Собственные компоненты HadoopDB
Как показывает рис. 4, в архитектуре HadoopDB присутствует ряд компонентов, расширяющих среду Hadoop MapReduce.
Коннектор баз данных (Database Connector)
Коннектор баз данных обеспечивает интерфейс между TaskTracker и независимыми СУБД, располагаемыми в узлах кластера. Этот компонент расширяет класс InputFormat и является частью соответствующей библиотеки. От каждого MR-задания в коннектор поступает SQL-запрос, а также параметры поключения к системе баз данных (указание драйвера JDBC, размер структуры выборки данных и т.д.).
Теоретически коннектор обеспечивает подключение к любой JDBC-совместимой СУБД. Однако в других компонентах HadoopDB приходится учитывать специфику конкретных СУБД, поскольку для них требуется по-разному оптимизировать запросы. В экспериментах, описываемых в , использовалась реализация коннектора для PostgreSQL, а в уже упоминается некоторая поколоночная система. В любом случае, для среды HadoopDB эта реализация обеспечивает естественное и прозрачное использование баз данных в качестве источника входных данных.
Каталог
В каталоге поддерживаются метаданные двух сортов: параметры подключения к базе данных (ее месторасположение, класс JDBC-драйвера, учетные данные) и описание наборов данных, содержащихся в кластере, расположение реплик и т.д. Каталог сохраняется в формате XML в HDFS. К нему обращаются JobTracker и TaskTracker для выборки данных, требуемых для планирования задач и обработки данных.
Загрузчик данных (Data Loader)
Обязанностями загрузчика данных являются:
-
глобальное разделение данных по заданному ключу при их загрузке из HDFS;
-
разбиение данных, хранимых в одном узле, на несколько более мелких разделов (чанков, chunk);
-
массовая загрузка данных в базу данных каждого узла с использованием чанков.
Загрузчик данных состоит из компонентов GlobalHasher и LocalHasher. GlobalHasher запускает в Hadoop MapReduce специальное задание, в котором читаются файлы данных HDFS и производится их разделение на столько частей, сколько имеется рабочих узлов в кластере. Сортировка данных не производится. Затем LocalHasher в каждом узле копирует соответствующий раздел из HDFS в свою файловую систему, разделяя его на чанки в соответствии с установленным в системе максимальным размером чанка.
В GlobalHasher и LocalHasher используются разные хэш-функции, обеспечивающие примерно одинаковые размеры всех чанков. Эти хэш-функции отличаются от хэш-функции, используемой в Hadoop MapReduce для разделения данных по умолчанию. Это способствует улучшению балансировки нагрузки.
Планирование SQL-запросов
Внешний интерфейс HadoopDB позволяет выполнять SQL-запросы. Компиляцию и подготовку планов выполнения SQL-запросов производит планировщик SMS (SMS Planner на рис. 4), являющийся расширением планировщика Hive .
Планировщик Hive преобразует запросы, представленные на языке HiveQL (вариант SQL) в задания MapReduce, которые выполняются над таблицами, хранимыми в виде файлов HDFS. Эти задания представляются в виде ориентированных ациклических графов (directed acyclic graph, DAG) реляционных операций фильтрации (ограничения), выборки (проекции), соединения, агрегации, каждая из которых выполняется в конвейере: после обработки каждого очередного кортежа результат каждой операции направляется на вход следующей операции.
Операции соединения, как правило, выполняются в задаче Reduce MR-задания, соответствующего SQL-запросу. Это связано с тем, что каждая обрабатываемая таблица сохраняется в отдельном файле HDFS, и невозможно предполагать совместного размещения соединяемых разделов таблиц в одном узле кластера. Для HadoopDB это не всегда так, поскольку соединяемые таблицы могут разделяться по атрибуту соединения, и тогда операцию соединения можно вытолкнуть на уровень СУБД.
Для пояснения того, как работает планировщик Hive, и каким образом его функциональность расширяется в SMS, невозможно обойтись без примера, и для простоты воспользуемся примером из . Пусть задан следующий простой запрос с агрегацией, смысл которого состоит в получении ежегодных суммарных доходов от продаж товаров:
SELECT YEAR(saleDate), SUM(revenue) FROM sales GROUP BY YEAR(saleDate);
В Hive этот запрос обрабатывается следующим образом:
Производится синтаксический разбор запроса, и образуется его абстрактное синтаксическое дерево.
Далее работает семантический анализатор, который выбирает из внутреннего каталога Hive MetaStore информацию о схеме таблицы sales, а также инициализирует структуры данных, требуемые для сканирования этой таблицы и выборки нужных полей.
Затем генератор логических планов запросов производит план запроса – DAG реляционных операций.
Вслед за этим оптимизатор перестраивает этот план запроса, проталкивая, например, операции фильтрации ближе к операциям сканирования таблиц. Основной функцией оптимизатора является разбиение плана на фазы Map и Reduce. В частности, перед операциями соединения и группировки добавляется операция переразделения данных (Reduce Sink). Эти операции отделяют фазу Map от фазы Reduce. Оценочная (cost-based) оптимизация не используется, и поэтому получаемые планы не всегда эффективны.
Генератор физических планов выполнения запросов преобразует логический план в физический, допускающий выполнение в виде одного или нескольких MR-заданий. Первая (и каждая аналогичная) операция Reduce Sink помечает переход от фазы Map к фазе Reduce некоторого задания MapReduce, а остальные операции Reduce Sink помечают начало следующего задания MapReduce. Физический план выполнения приведенного выше запроса, сгенерированный планировщиком Hive, показан на рис. 5.
Полученный DAG сериализуется в формате XML. Задания инициируются драйвером Hive, который руководствуется планом в формате SQL и создает все необходимые объекты, сканирующие данные в таблицах HDFS и покортежно обрабатывающие данные.
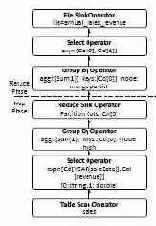
Рис. 5. Задание MapReduce, генерируемое Hive
В планировщике SMS функциональность планировщика Hive расширяется следующим образом. Во-первых, до обработки каждого запроса модифицируется MetaStore, куда помещается информация о таблицах базы данных. Для этого используется каталог HadoopDB (см. выше).
Далее, после генерации физического плана запроса и до выполнения MR-заданий выполняются два прохода по физическому плану. На первом проходе устанавливается, какие столбцы таблиц действительно обрабатываются запросом, и определяются ключи разделения, используемые в операциях Reduce Sink.
На втором проходе DAG запроса обходится снизу-вверх от операций сканирования таблиц до формирования результата или первой операции Reduce Sink. Все операции этой части DAG преобразуются в один или несколько SQL-запросов, которые проталкиваются на уровень СУБД. Для повторного создания кода SQL используется специальный основанный на правилах генератор.

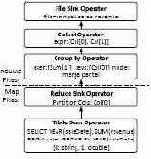
Рис. 6. Варианты MR-заданий, генерируемые SMS
На рис. 6 показаны два плана, которые производит SQL для приведенного выше запроса. План в левой части рисунка производится в том случае, если таблица sales является разделенной по YEAR(saleDate). В этом случае вся логика выполнения запроса выталкивается в СУБД. Задача Map всего лишь записывает результаты запроса в файл HDFS.
В противном случае генерируется план, показанный в правой части рис. 6. При выполнении запроса по этому плану на уровне базы данных производится частичная агрегация данных, а для окончательной агрегации требуется выполнение задачи Reduce, производящей слияние частичных результатов группировки, которые получены в каждом узле на фазе задачи Map.