Предпосылки и преимущества использования механизма SQL/MapReduce
По мнению основных разработчиков СУБД nCluster, декларативный язык SQL во многом ограничивает использование аналитических СУБД. С одной стороны, несмотря на постоянное наращивание аналитических возможностей этого языка, для многих аналитиков их оказывается недостаточно. С другой стороны, эти возможности постепенно становятся такими сложными и непонятными, что зачастую становится проще написать процедурный код, решающий частную аналитическую задачу. Наконец, оптимизаторы запросов SQL-ориентированных СУБД постоянно отстают от развития языка, и планы сложных аналитических запросов могут быть весьма далеки от оптимальных, что приводит к их недопустимо долгому выполнению, а иногда и аварийному завершению.
Эти проблемы частично решаются за счет поддержки в SQL-ориентированных СУБД механизма функций, определяемых пользователями (User-Defined Function, UDF). Такие функции позволяют пользователям решать внутри сервера баз данных свои прикладные задачи путем написания соответствующего процедурного кода. Однако традиционные механизмы UDF разрабатывались в расчете на "одноузловые" СУБД, и по умолчанию предполагается чисто последовательное выполнение UDF. Как упоминалось в этом разделе ранее, автоматическое распараллеливание последовательного кода в массивно-параллельной среде с разделением данных является сложной нерешенной проблемой.
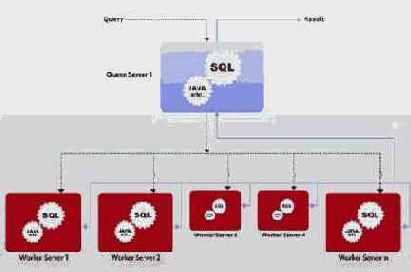
Рис. 2. Совместное выполнение SQL-запросов и SQL/MapReduce-функций в nCluster
В Aster Data для обеспечения механизма естественно распараллеливаемых UDF разработана инфраструктура SQL/MapReduce, поддерживаемая внутри SQL-ориентированной массивно-параллельной СУБД nCluster (см. рис. 2, позаимствованный из ). Организация среды SQL/MapReduce обеспечивает следующие возможности:
-
можно эффективно выполнять в "реляционном" стиле операции над таблицами с использованием SQL, а "нереляционные" задачи и оптимизации – возлагать на явно программируемые процедурные функции;
-
поскольку функции выполняются над согласованными данными из таблиц базы данных, обеспечивается согласованность вычислений;
-
оценочный (cost-based) оптимизатор может принимать решения о способе выполнения SQL-запросов, содержащих вызовы SQL/MapReduce-функций, на основе достоверной статистики данных;
пользователи nCluster могут формулировать SQL-запросы с использованием высокоуровневых средств анализа данных, воплощенных в SQL/MapReduce-функциях.
SQL/MapReduce-функции можно программировать как на традиционных языках программирования (Java, C#, C++), так и скриптовых языках (Python, Ruby). При этом, независимо от используемого языка программирования, эти функции являются самоописываемыми и полиморфными. Поскольку здесь идет речь о табличных функциях (т.е. функциях, входными параметрами и результатами которых являются таблицы), то это означает, что одна и та же функция может принимать на вход таблицы с разными схемами (функция настраивается на конкретную схему входной таблицы на этапе формирования плана запроса, содержащего ее вызов) и выдавать таблицы также с разными схемами (функция сама сообщает планировщику запроса схему своего результата на этапе формирования плана запроса). Это свойство SQL/MapReduce-функций упрощает процедуру их регистрации в системе (в частности, не требуется выполнение специального оператора SQL CREATE FUNCTION, в котором описывались бы схемы входной и выходной таблиц) и способствует повторному использованию кода.
Синтаксические особенности определения SQL/MapReduce-функций и их семантика делают эти программные объекты естественным образом параллелизуемыми по данным: во время выполнения для каждой функции образуются ее экземпляры, параллельно выполняемые в узлах, которые содержат требуемые данные. Вызовы функций подобны подзапросам SQL, что обеспечивает возможность композиции функций, при которой при вызове функции вместо спецификации входной таблицы можно задавать вызов другой функции. Наконец, внешняя эквивалентность вызова SQL/MapReduce-функции подзапросу позволяет применять при формировании плана SQL-запроса с вызовами таких функций обычную оценочную оптимизацию на основе статистики, а также динамически изменять порядок выполнения функций и вычисления настоящих SQL-подзапросов.
В следующем пункте без излишних деталей обсуждаются синтаксические конструкции, семантика и особенности реализации, обеспечивающие отмеченные свойства SQL/MapReduce-функций (более подробное описание см. в ).