Диаграммы взаимодействия объектов
Диаграммы взаимодействия объектов позволяют проанализировать обмен сообщениями между объектами на более тонком уровне детализации, чем модель потока данных.
Диаграммы взаимодействия объектов неоценимы, если требуется описать взаимодействие между различными системами. Они позволяют определить, какая информация содержится в каком сообщении. Поскольку эти сообщение написаны на языке XML, диаграммы взаимодействия объектов дают нам контекст, требуемый для начала проектирования структуры XML каждого индивидуального сообщения.
Динамическая информационная модель
Динамические модели описывают, что происходит с информацией: примерами таких моделей являются диаграммы рабочих процессов, потоков данных и жизненных циклов объектов. Динамические модели состоят примерно из таких утверждений: "Отделение патологии отправит результаты теста консультанту, отвечающему за пациента". Динамические модели описывают процесс обмена информацией: данные отправляются из одного места в другое с конкретной целью.
Для построения динамической модели можно воспользоваться различными программными системами (например, диаграммы рабочих процессов и диаграммы потоков данных можно построить, воспользовавшись программой BPWin).
Существует несколько подходов к динамическому моделированию:
Модели рабочих процессовМодели потоков данныхОбъектные моделиЖизненные циклы объектовВарианты использованияДиаграммы взаимодействия объектов
Этап 1. Именование понятий
Для начала нужно составить список понятий, относящихся к системе. Иногда предлагают даже описать систему на бумаге и выделить все существительные. В любом случае этот этап, как правило, не представляет затруднений.
Далее, и это иногда требует больше времени, надо описать типы объектов. Описание термина должно быть точным, чтобы не возникало разногласий по существу определения. Ценность моделирования в том и заключается, что оно предотвращает появление потенциальных источников непонимания.
По завершении работы, вероятно, получится длинный список типов объектов, и у некоторых будут длинные имена. Следует выбирать такие имена, которые занятые в этом бизнесе люди смогут корректно понять и интерпретировать: дело в том, что они не всегда будут сверяться с написанными определениями.
Помимо именования типов объектов стоит определить также, каким образом можно идентифицировать индивидуальные экземпляры. Возможно, в этом виде бизнеса существует код, который следует знать, или написать его. Надо принимать во внимание, что в схемах кодирования в бизнесе часто обнаруживаются проблемы.
В конце этого этапа мы получим список типов объектов с именами и определениями, по поводу которых достигнуто соглашение.
Этап 2: Таксономия
Таксономия - это термин, используемый в биологии для обозначения системы классификации; в информационном моделировании ее также называют иерархией типов (иногда ее называют еще онтологией). Перечислив и назвав типы объектов, их надо организовать в иерархическую схему классификации. Часто эти иерархические отношения возникают уже на этапе определения типов объектов.
Ключевой здесь является фраза, определяющая принадлежность (в английском языке - is или is kind of). Написав предложение вида "А есть разновидность В" или "Каждое А есть В", вы определили отношения подтипов в вашей таксономии.
Иногда эти действия называются тестом "is а" ("есть", "представляет собой"). Однако будьте внимательны, поскольку эта конструкция используется также и для описания отношений между конкретным экземпляром и его типом, безопаснее писать этот тест в форме "is a kind of" ("представляет собой разновидность").
Идентификация подтипов бывает, полезна при проектировании документа, что более важно, она помогает лучше понять определения типов объектов.
Если вы занимались объектно-ориентированным программированием, то понимаете, как определять иерархии типов. Но программисты часто рассматривают классы объектов, прежде всего в терминах модулей функциональности внутри системы, а не понятий, которые они представляют в окружающем мире. Тогда для обозначения типов объектов используются глаголы, а не существительные - что неверно.
Итак, этап 2 сводится к организации типов объектов в иерархию типов.
Этап 3: Поиск связей
После того как объекты названы, в статическом информационном моделировании надо определить связи, существующие между ними. Связи (на языке UML они называются ассоциациями) можно показать просто сформулировав их в виде обычных предложений или их можно показать графически в виде диаграммы. Для диаграмм, описывающих связи между объектами, существует большое количество нотаций, каждый может выбрать более предпочтительную для себя. Диаграммы следует делать предельно простыми и интуитивно понятными, сосредоточившись на ключевых сообщениях и оставив подробности текстовым документам, которые проще обслуживать.
Существует некая информация, которую надо знать о каждой связи:
Множественность связи показывает сколько объектов каждого типа принимать в ней участие. Связи типа "один-ко-многим": одна глава содержит много параграфов, один человек покупает много туристических поездок.Связи типа "многие-ко-многим" также часто встречаются: один автор может написать несколько книг, но у книги также может быть несколько авторов.Связи типа "один-к-одному".
При моделировании информации для окончательного представления XML особенно важным типом связей являются связи включения. Множественность этих связей всегда бывает "один-ко-многим" и "один-к-одному". Хотя четкого правила по поводу того, какие объекты образуют связи включения, не существует, можно иногда использовать правила обычного языка: глава содержит параграфы, курорт содержит отели, а отель содержит посетителей. В языке UML определено две формы связей включения. Первая - это агрегации, относительно свободное объединение объектов, позволяющее рассматривать их группу в течение некоторого времени как целое (например, туристическая группа, одни и те же люди могут в разное время входить в разные группы). Вторая форма - композиция. Это более строгая форма; отдельные части целого не могут существовать независимо от него (например, комнаты в отеле не могут существовать независимо от отеля).
Найти подходящие имена для связей иногда бывает нелегко. При записи связей полезно использовать полные фразы типа "отель расположен на курорте" или "человек - это автор книги". Нам не надо использовать эти имена в тегах разметки XML, они присутствуют только в документации на систему.
Итак, в конце этапа 3 мы определили связи существующие между типами объектов в нашей модели.
Этап 4. Описание свойств
Типы объектов и связи формируют скелет статической информационной модели; свойства можно сравнить с плотью на костях. Свойства представляют собой простые значения, ассоциированные с объектами. У человека можно определить рост, вес, национальность и род занятий; отель имеет определенное количество комнат, этажность и ценовую категорию.
Не следует снова включать связи в список свойств объекта: расположение отеля не является его свойством, если мы уже промоделировали его как связь с курортом.
Главное, что нам надо знать о свойствах, - это тип их данных. Определен ли для них фиксированный диапазон значений, являются ли они числовыми, в каких единицах выражаются? Является ли свойство обязательным и есть ли у него значение по умолчанию?
В конце этапа 4 мы завершили формирование статической информационной модели: получили полное описание типов объектов в системе, их связей друг с другом и их свойств.
Контрольные вопросы:
Дать определение статической информационной модели. Какие этапы необходимо пройти при построении статической информационной модели. В чем заключается этап "идентификация понятий" при построении статической информационной модели. В чем заключается этап "организация понятий в иерархию классов" при построении статической информационной модели. В чем заключается этап "определение связей" при построении статической информационной модели. В чем заключается этап "описания свойств" при построении статической информационной модели. Дать определение динамической информационной модели. Что представляют собой модели рабочих процессов. Что представляют собой модели потоков данных. Что представляют собой объектные модели. Что описывают жизненные циклы объектов. Что описывают варианты использования. Что описывают диаграммы взаимодействия объектов.

<
Методические указания
Существуют два основных типа информационной модели: статическая и динамическая.
Модели потоков данных
Модели потоков данных очень напоминают предыдущий тип, но здесь основное внимание уделяется информационным, а не бизнес- систем. Эта модель описывает хранилища данных (data stores), где информация находится постоянно (это может быть база данных в компьютере или просто кабинет с папками), процессоры, манипулирующие с этими данными, и потоки данных, передающие данные от одного процессора другому. Она активно использует статическую информационную модель: последняя описывает, что означают такие концепции, как путешественник или отель, но ничего не сообщает о том, где содержится информация. Напротив, из модели потоков данных становится ясно, что информация о туристической поездке находится в базе данных покупок до завершения поездки и оплаты всех счетов, после чего резюме этой информации передается в маркетинговую информационную систему, а все остальное - в архив.
Модели рабочих процессов
Модели рабочих процессов заостряют внимание на роли людей и организаций в выполнении работы, хранение и обработка информации играют в них вторичную роль. Модель процесса описывает, например, что будет с путешественником, если на отдыхе с ним произойдет несчастный случай. Она определяет, за какие действия отвечает локальный представитель на курорте, агент в стране, где находи курорт и главный офис. В результате становится ясно, кто должен отвечать за организацию медицинской помощи, за перевозку туриста домой и за информирование родственников. Она может описывать различные формы, заполняемые и пересылаемые между участниками, и вообще не привлекать компьютерные системы. Модель процесса обычно фокусирует внимание на ролях, обязанностях и задачах каждого действующего лица системы (actor), а workflow-модель имеет дело с документами, передаваемыми между действующими лицами. Модели потоков данных.
Объектные модели
Объектные модели содержат как динамический, так и статический компоненты. Динамическая или поведенческая часть определения объекта сосредоточена на том, что может делать или делал каждый объект, представляя для этого набор операций или методов, описывающих его действия.
Содержание работы
Изучить основные принципы построения статической и динамической модели.Построить статическую и динамическую модель для заданного варианта.Оформить отчет, включающий постановку задачи, статическую и динамическую модели.Защитить лабораторную работу.
Статическая информационная модель
В статической модели описываются допустимые состояния системы. В статических моделях описываются типы объектов в системе, их свойства и связи. Описывая объекты, они определяют, разумеется, и их имена. Достичь соглашения по именованию всех объектов означает выиграть половину битвы, именно поэтому информационные модели XML иногда называют словарями.
При построении статической информационной модели необходимо пройти следующие этапы:
Этап 1. Идентификация понятий, присвоение им имен и их определение
Этап 2. Организация понятий в иерархию классов
Этап 3. Определение связей, множественности и ограничений
Этап 4. Добавление свойств для конкретизации деталей значений, связанных с объектами
Варианты использования
Варианты использования (use cases) анализируют выполнение специфических задач пользователя (например, человек, купивший туристическую поездку, отменяет свой заказ). Вариант использования напоминает модель процесса, но в общем случае заостряет внимание на деятельности одного конкретного пользователя.
Варианты использования могут быть полезны как на этапе моделирования деловой активности, так и при описании внутреннего поведения информационных систем. Одна из опасностей заключается в смешении двух уровней. Лучше этого не делать, поскольку они представляют интерес для различных аудиторий.
Представленный в виде варианта использования диалог пользовательского интерфейса описывает, какой информацией пользователь обмениваются с системой, а не то, как она представлена на экране. Это естественным образом приводит к реализации XML, в которой информационное содержание отделено от особенностей представления.
Жизненные циклы объекта
Жизненные циклы объекта (на языке UML это называется линиями жизни объекта) также заостряют внимание на индивидуальных объектах, но придерживаются более целостного подхода. Они описывают, что происходит с объектом на протяжении его жизни: как он создается, какие события с ним происходят, как он реагирует на эти события и какие условия приводят в конце к его разрушению.
Жизненные циклы объекта очень полезны для тестирования завершенности модели. Часто наблюдается тенденция к акцентированию внимания только на некоторых событиях за счет остальных. Пока мы не определим, каким образом каждый объект попадает в систему и как он удаляется из нее, полного понимания не будет.
DOM и базы данных
Язык XML предоставляет идеальный механизм обмена информацией между различными базами данных. По своей природе базы данных являются закрытыми - в каждой базе используется своя структура имен элементов, свой уровень нормализации и даже свои методы описания перечисляемой информации. С помощью модели DOM можно упростить передачу информации между различными базами данных.
Использование модели DOM на сервере
Поскольку разработчики Интернет -приложений имеют значительно больший контроль над программным обеспечением, устанавливаемым на их серверах, первые приложения DOM, как правило, были нацелены именно на эту область. Модель DOM позволяет существенно упростить обмен данными между различными деловыми системами, а также предоставляют идеальный механизм для архивирования и извлечения данных.
Использование модели DOM у клиента
В настоящее время становится все более важно, чтобы документ можно было читать различными клиентами. Эти клиенты могут визуализировать документ по-разному, в зависимости от типа клиента и назначения файла. Пользовательский браузер с помощью модели DOM изучит дерево узлов документа и отобразит необходимую клиенту информацию.
По мере интеграции модели DOM в основные браузеры станет возможно с помощью манипуляций документами XML у клиента добиваться более эффективного взаимодействия с пользователями. Структурированную информацию можно собирать у клиента и отправлять на сервер за одну транзакцию, а не с помощью нескольких обращений к формам, находящимся на различных страницах HTML.
Так же возможно широкое использования модели DOM для генерации и манипулирования документами XML в среде предприятия.
Клиент и сервер
Все приложения DOM и XML можно разделить на две группы: устанавливаемые на сервере (или в таком контролируемом окружении, как системы типа клиент/сервер) и устанавливаемые у клиента.
Модель DOM в окружающем мире
Компания Netscape в версии 4.7 своего браузера еще не предлагает встроенной поддержки DOM, но при наличии библиотек ActiveX или Java DOM можно обращаться к документам XML и работать с ними у клиента с помощью языков Java и JavaScript. Следующие версии браузера Netscape включает встроенную поддержку XML и XSL.
В браузерах Internet Explorer 5 и выше находятся встроенные библиотеки DOM и поддержка XSL. Для сценариев на стороне клиента доступно множество объектов для работы с XML-документом, самые важные из них, объекты XMLDOMDocument, XMLDOMNode, XMLDOMNodeList, XMLDOMParseError представляющие интерфейс для доступа ко всему документу, отдельным его узлам и поддеревьям, предоставляющие необходимую для отладки информацию о произошедших ошибках анализатора соответственно.
Объект XMLDOMDocument
Объект XMLDOMDocument представляет верхний уровень объектной иерархии и содержит методы для работы с документом: его загрузки, анализа, создания в нем элементов, атрибутов, комментариев и т.д. Многие свойства и методы этого объекта реализованы также в классе Node, т.к. документ может быть рассмотрен как корневой узел с вложенными в него поддеревьями.
Объект XMLDOMNode
Объект XMLDOMNode, реализует базовый DOM интерфейс Node, предназначен для манипулирования с отдельным узлом дерева документа. Его свойства и методы позволяют получать и изменять полную информацию о текущем узле - его тип (является ли текущий узел элементом, комментарием, текстом и т.д.), название, полное название (вместе с Namespace префиксом), его содержимое, список дочерних элементов и т.д.
Объект XMLDOMNodeList
Представляет собой список узлов - поддеревья и содержит методы, при помощи которых можно организовать процедуру обхода дерева.
Объект XMLDOMParserError
Объект позволяет получить всю необходимую информацию об ошибке, произошедшей в ходе разбора документа. Все свойства этого объекта доступны только для чтения.
Объектная модель документа
В течение некоторого времени термин "объектная модель документа" применялся к Web-браузерам. Такие объекты, как окно, документ и история, считались частью объектной модели браузера, но в различных браузерах эти объекты реализованы по-разному. Для создания более стандартизированного способа обращения и манипулирования структурами документов в сети консорциум W3C предложил спецификацию W3C DOM представляющую собой не зависящее от языка или платформы определение. W3C DOM модель устанавливает стандартную функциональность для навигации по документу и манипулирования содержанием и структурой документов, написанных на языках XML и HTML.
При использовании DOM для работы с текстовым файлом в формате XML она анализирует файл, разбивает его на индивидуальные элементы, атрибуты, комментарии и т.д. Затем в памяти создается представление файла XML в виде дерева узлов в котором каждый объект в документе рассматривает в виде узла: элементы, атрибуты, комментарии, команды обработки и даже составляющий атрибуты обыкновенный текст. Для следующего фрагмента XML документа:
<tree-node> <node-level1> <node-level2/> <node-level2>text</node-level2> <node-level2/> </node-level1> <node-level1> <node-level2>text</node-level2> </node-level1> <node-level1> <node-level2/> <node-level2> <node-level3/> </node-level2> </node-level1> </tree-node>
дерево элементов выглядит так:
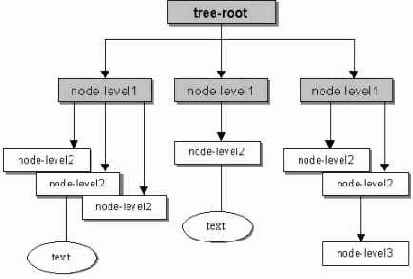
После этого разработчик может обращаться к содержанию документа, используя дерево узлов, и при необходимости вносить в него изменения, например чтобы добавить новый элемент( для этого достаточно просто создать новый узел и прикрепить его в качестве потомка к нужному узлу).
В W3C DOM для различных составляющих DOM объектов определены интерфейсы облегчающие манипулирование с деревом узлов, но для этих интерфейсов не предлагается никакой специфической реализации, и ее можно осуществить на любом языке программирования. Определяемая консорциумом W3C модель DOM не зависит от платформы, т.е. W3C определяет, какие методы и свойства должны быть сделаны доступными в реализациях, специфических для конкретных систем, но не подробности осуществления этих реализации. Реализуя приложение использующие модель DOM, а не спецификации W3C, разработчики должны ссылаться на документацию, специфическую для данной реализации, которую можно найти в библиотеках. Например, компания Microsoft предоставляет такую документацию для своей версии XML DOM по адресу http://msdn.microsoft.com/xml/reference/xmldom/start.asp.
Применение DOM для создания комплексных документов XML
Модель DOM - это модель с произвольной выборкой, т.е. узел может быть создан или прикреплен в любом месте дерева XML в любой момент времени. Эта особенность очень полезна при создании документов XML на основе информации иерархической или реляционной базы данных.
Создать документ XML с помощью модели DOM значительно проще, чем записывать информацию в текстовый файл. Вместо того чтобы все время перемещаться между таблицами в поисках требуемой информации, всю информацию из каждой таблицы можно записать одновременно. С увеличением глубины дерева узлов первый метод становится все более и более запутанным, в то время как второй легко масштабируется. Кроме того, генерация документа с помощью модели DOM гарантирует его правильное оформление.
и проходит все узлы, используя
| <html> <!-- Эта программа загружает XML-документ в браузер IE5 и проходит все узлы, используя рекурсивную функцию, применяя к ним необходимый стиль оформления --> <!-- Загружаем XML-документ--> <XML ID="xdoc" SRC="documents.xml"></XML7gt; 7lt;SCRIPT7gt; //Создаем объект документа var myDoc=xdoc; //Просматриваем документ применяя к каждому тегу свой стиль оформления --> x=getchildren(myDoc); //***************Начало рекурсивной функции************* function getchildren(node) { var x=node.childNodes; var z=x.length; if (z!=0) { for(var i=0;i<z;i++) { if (x(i).nodeType==3) { document.write(x(i).nodeValue); document.write(); getchildren(x(i)); } else if (x(i).nodeName=="title") { document.write("<DIV STYLE='font-size:20pt;color:red;'>"); getchildren(x(i)); document.write("</DIV>"); document.write("</br>"); } else if (x(i).nodeName=="type") { document.write("<DIV STYLE='font-size:14pt;color:black;'>"); getchildren(x(i)); document.write("</DIV>"); document.write("</br>"); } else if (x(i).nodeName=="file") { document.write("<DIV STYLE='font-size:16pt;'>"); document.write("<a href="); getchildren(x(i)); document.write(">"); document.write("Файл"); document.write("</a>"); document.write("</DIV>"); document.write("</br>"); } else { getchildren(x(i)); } } } } </SCRIPT> </html> |
| Листинг 6.1. |
| Закрыть окно |
x=getchildren(myDoc);
//***************Начало рекурсивной функции*************
function getchildren(node)
{
var x=node.childNodes;
var z=x.length;
if (z!=0)
{
for(var i=0;i
Пример использования модели DOM.
Рассмотрим простейший пример обработки XML документа с использованием DOM модели.
Рассмотрим следующий XML документ:
<example type="listing"> <?xml version="1.0" encoding="windows-1251"?> <?xml-stylesheet type='text/xsl' href='1.xsl'?> <book> <title>Языки информационного обмена </title> <type> Лекции </type> <file>Лекции.doc</file> </book>
Для отображения данного документа можно использовать следующий простой рекурсивный цикл.
<html> <!-- Эта программа загружает XML-документ в браузер IE5 и проходит все узлы, используя рекурсивную функцию, применяя к ним необходимый стиль оформления --> <!-- Загружаем XML-документ--> <XML ID="xdoc" SRC="documents.xml"></XML7gt; 7lt;SCRIPT7gt; //Создаем объект документа var myDoc=xdoc; //Просматриваем документ применяя к каждому тегу свой стиль оформления --> x=getchildren(myDoc); //***************Начало рекурсивной функции************* function getchildren(node) { var x=node.childNodes; var z=x.length; if (z!=0) { for(var i=0;i<z;i++) { if (x(i).nodeType==3) { document.write(x(i).nodeValue); document.write(); getchildren(x(i)); } else if (x(i).nodeName=="title") { document.write("<DIV STYLE='font-size:20pt;color:red;'>"); getchildren(x(i)); document.write("</DIV>"); document.write("</br>"); } else if (x(i).nodeName=="type") { document.write("<DIV STYLE='font-size:14pt;color:black;'>"); getchildren(x(i)); document.write("</DIV>"); document.write("</br>"); } else if (x(i).nodeName=="file") { document.write("<DIV STYLE='font-size:16pt;'>"); document.write("<a href="); getchildren(x(i)); document.write(">"); document.write("Файл"); document.write("</a>"); document.write("</DIV>"); document.write("</br>"); } else { getchildren(x(i)); } } } } </SCRIPT> </html>
Листинг 6.1.
Функция getchildren кода принимает в качестве параметра узел, создает список всех дочерних узлов, проходит по этому списку, проверяя, имеет ли каждый дочерний узел свои собственные дочерние узлы, и если имеет, то вызывает сама себя. При этом к тегам с именами title, type, file применяются соответствующие стили.
Применив эту функцию к нашему XML- документу мы получим на экране следующий результат:
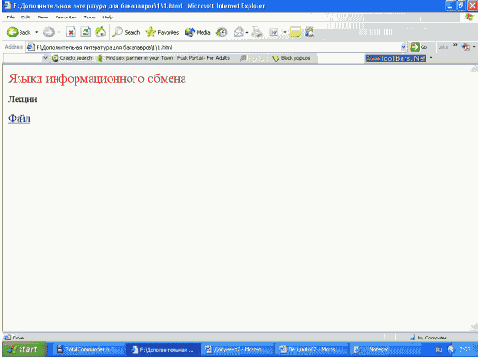
<
Зачем нужна модель DOM
В качестве метода доступа к файлам XML всегда следует выбирать модель DOM. По сравнению с такими доступными механизмами генерации документов XML, как запись непосредственно в поток, этот метод имеет ряд преимуществ:
Модель DOM гарантирует правильную грамматику и правильное оформление документов.
DOM трансформирует текстовый файл в абстрактное представление дерева узлов. Это позволяет полностью избежать таких проблем, как незакрытые или неправильно вложенные теги. Работая с документом XML при помощи этого метода, разработчик должен беспокоиться не о текстовом выражении документа, а только о связях типа родитель-потомок и об относящейся к этому информации. Кроме того, DOM предотвращает создание неправильных связей родитель-потомок в документе.
Модель DOM абстрагирует содержание от грамматики.
Созданное моделью DOM дерево узлов - это логическое представление содержания файла XML, показывающее, какая информация в нем представлена и как ее фрагменты соотносятся друг с другом, вне непосредственной связи с грамматикой XML. Информация дерева узлов используется для обновления реляционной базы данных или для создания страницы HTML, и разработчики при этом не должны вникать в специфику языка XML.
Модель DOM упрощает внутреннее манипулирование документом.
Задача разработчика, использующего модель DOM для модификации внутренней структуры файла XML, упрощается по сравнению с работой тех, кто для этой цели применяет традиционные механизмы манипулирования файлами. Как уже было, описано DOM позволяет легко добавить элемент в середину документа. Кроме того, такие глобальные операции, как удаление из документа всех элементов с конкретным именем тега, могут быть выполнены с помощью пары команд, а не "метода грубой силы", предполагающего полное сканирование всего файла и удаление ненужных тегов.
Модель DOM напоминает структуры иерархических и реляционных баз данных.
Способ, используемый DOM для представления связей между элементами данных, напоминает метод представления этой информации в современных иерархических и реляционных базах данных. С помощью этой модели упрощается процесс обмена данными между файлом XML и базой данных. Использование модели DOM для построения иерархической структуры документа позволяет легко передавать информацию между системами.
Декларация пространства имен
Поскольку в разных языках разметок - реализациях XML - могут встретится одни и те же имена тегов и их атрибутов, имеющие совершенно разный смысл, надо иметь возможность их как-то различать. Для этого имена тегов и атрибутов снабжают кратким префиксом, который отделяется от имени двоеточием. Префикс имени связывается с идентификатором, определяющим пространство имен (namespace). Все имена тегов и атрибутов, префиксы которых связаны с одним и тем же идентификатором, образуют одно пространство имен, в котором имена должны быть уникальны.
Поскольку необходимо, чтобы, встретив декларацию пространства имен каждый мог распознать ее, для него зарезервируем специальное слово. В соответствии с рекомендацией пространств имен, это слово xmlns. Значением атрибута является идентификатор URI, определяющий используемое пространство имен. Часто это адрес URL определения DTD, но так должно быть не всегда. Префикс и идентификатор пространства имен определяются атрибутом xmlns следующим образом:
<ntb:notebook xmlns:ntb = "http://some.firm.com/2003/ntbml">
Как видите, префикс ntb только что определен, но его уже можно использовать в имени ntb:notebook. В дальнейшем имена тегов и атрибутов, которые мы хотим отнести к пространству имен http://some.firm.com/2003/ntbml, снабжаются префиксом ntb, например:
<ntb:city ntb:type="поселок">Горелово</ntb:city>
Кроме того, в одном теге могут встречаться сразу несколько пространств имен. Ниже приводится пример смешения нескольких пространств имен:
<catalog:book order:ISBN = "1-861003-11-0">
Элемент book взят из пространства имен catalog, а атрибут ISBN - из order.
Имя вместе с префиксом, например
ntb:notebook
или
ntb:city
называется расширенным, уточенным или квалифицированным именем (OName. Qualified Name). Часть имени, записанная после двоеточия, называется локальной частью (local part) имени.
Номенклатура названий Web-ресурсов может запутать. Универсальный указатель ресурса (Uniform Resource Locator, URL) указывает на ресурс в терминах протокола доступа и расположения в сети.
Универсальный идентификатор ресурса ( Uniform Resource Identifier, URI) представляет собой уникальное имя некоторого ресурса. Смотрите на URI просто как на уникальную строку символов, идентифицирующую пространство имен.
По правилам SGML и XML, двоеточие может применяться в именах как обычный символ, поэтому имя с префиксом - это просто фокус, всякая программа, "не знающая" пространства имен, анализируя документ, рассматривает уточненное имя как обычное имя. Отсюда следует, в частности, что в объявлении типа документа (Document Type Declaration) нельзя опускать префиксы имен.
Атрибут xmlns может появиться в любом элементе XML, а не только в корневом. Определенный им префикс можно применять в том элементе, в котором записан атрибут xmlns, и во всех вложенных в него элементах. Более того, в одном элементе можно определить несколько пространств имен.
Во вложенных элементах пространство имен можно переопределить, связав префикс с другим идентификатором.
Появление имени тега без префикса в документе, использующем пространство имен, означает, что имя принадлежит пространству имен по умолчанию (default namespace).
Хорошо оформленный документ должен использовать пространств имен для всех своих элементов.
Префиксы, начинающиеся с символов xml с любым регистром букв, зарезервированы за самим языком XML. Префикс xmlns используется для связи другого, определяемого, префикса с идентификатором его пространства имен. Префикс xmlns не нужно определять, он введен рекомендацией "Namespaces in XML" и связан там с идентификатором пространства имен http://www.w3.ori/2000 /xmlns/.
Еще один префикс, xml, связан в той же рекомендации с идентификатором http://www.w3.org/XML/1998/namespace. Его тоже не надо определять в документе XML. Никакой другой префикс не может быть связан с этими идентификаторами.
Пока есть только два атрибута с префиксом xml. Для каждого элемента верного документа, в котором используются эти атрибуты, они должны быть объявлены в описании DTD (Document Type Definition).
Атрибут xml:lang определяет язык, используемый в содержимом элемента. Например, xml:lang="us", xml:lang="en-US", xml:lang="ru-RU". Атрибут можно использовать так:
<р xml:lang="ru_RU" >3апись на русском языке</р>
Атрибут xml:space указывает программе-обработчику, как следует обрабатывать пробельные символы (пробелы, знаки горизонтальной табуляции и символы перевода строки), записанные в содержимом элемента. У атрибута есть всего два значения. Значение preserve предписывает сохранять пробельные символы в неприкосновенности. Это важно для некоторых текстов, например, программных кодов. Значение default оставляет пробельные символы на усмотрение программы-обработчика.
Формат описания ресурсов
Формат описания ресурсов (Resource Description Framework) играет главную роль в процессе создания метаданных. Он позволяет проектировщикам описывать объекты, добавлять свойства для их более полного описания и определения, а также формировать такие сложные утверждения о них, как утверждения о связях между ресурсами. Спецификации языка содержатся в двух разделах:
Модель и синтаксисСхемы RDF
Базовая модель RDF охватывает модель описательных данных, которую можно выразить на языке XML, а также и другие виды синтаксиса. Разработанные при помощи RDF схемы могут определять не только домена и структуры, но также делать выводы об отношениях между обсуждаемыми объектами. RDF - сложный язык, но он обладает большими выразительными возможностями, и поэтому его сложность оправдана.
RDF "стоит на трех китах": это ресурсы, свойства и утверждения.
Квалифицированная область действия
Описанный выше метод работает хорошо, если вы можете четко разделить ваши пространства имен. Но иногда бывает необходимо включить в документ отдельные имена из внешних пространств имен. Вместо того чтобы декларировать пространства имен для целой области, можно использовать квалифицированные имена. Объявите нужные вам пространства имен в начале документа, а затем квалифицируйте их в месте использования.
Область действия
У деклараций пространств имен имеется область действия, так же, как у деклараций переменных в языках программирования. Это важно, так как пространства имен не всегда декларируются в начале документа XML, иногда это делается в последующих его разделах. Декларация пространства имен применима к элементу, в котором она появляется, а также к потомкам этого элемента, даже если она не определена там явным образом. Имя может ссылаться на пространство имен, только если используется в области действия его декларации.
Однако нам потребуется также смешивать области действия пространств имен в элементах, которые в противном случае наследовали бы другие пространства имен. В связи с этим определены два способа декларации области действия- default (по умолчанию) и qualified (квалифицированный).
Область действия по умолчанию
Как и следовало ожидать, необходимость добавления префикса к каждому имени в документе быстро становится утомительной. Фактически, введя концепцию области действия имени, мы можем смешивать в нашем документе большое количество префиксов. Если мы определяем пространство имен по умолчанию, то предполагается, что ему принадлежат все неквалифицированные имена внутри области действия его декларации. Таким образом, пространство имен, объявленное по умолчанию в корневом элементе, считается пространством по умолчанию для всего документа и может быть перекрыто только более специфическим пространством имен, объявленным внутри документа.
Чтобы пространство имен сделать пространством имен по умолчанию для некоторой области, достаточно опустить декларацию префикс.
Если префикс объявлен, а затем использован совместно с именем, то говорят что пространство имен явным образом установлено. Чтобы отнести к пространству имен неквалифицированное имя, необходимо объявить пространство по умолчанию, которое включает это неквалифицированное имя (без префикса).
Описание содержания документа
Предложение Document Content Description (DCD, описание содержания документа) поступило сразу после XML-Data. Это предложение представляет собой словарь RDF, явным образом предназначенный для декларации словарей XML. Его разработчики использовали выразительную мощь одного из стандартов представления метаданных - RDF - для создания стандарта с более ограниченной областью применения. Приблизительно это напоминает то, что язык XML является упрощенным множеством SGML.
Язык DCD синтаксически напоминает XML-Data, хотя в нем и отсутствуют некоторые углубленные возможности последнего. Он строго ориентирован на определение словарей XML. Однако в этом языке сохраняется характерная для XML-Data поддержка сильной типизации данных, а также наследование элементов. Как и XML-Data, DCD разрешает проектировщику объявлять модель схемы открытой или закрытой. Но в отличии от XML-Data, DCD для этой цели использует тот же механизм, что и для определений элементов. DCD, так же, как и XML-Data, позволяет налагать ограничения на значение содержания элементов.
Основанный на языке RDF, DCD является попыткой решения проблем определений DTD. Можно сказать, что в нем широкая мощность языка обменивается на направленную простоту. DCD - наиболее простой из языков описания метаданных. Он непосредственно решает существующие проблемы DTD и отказывается от их углубленной проработки, чтобы получить легко реализуемый стандарт схем XML.
Проблемы определений DTD
У определений DTD имеется ряд недостатков, которые выявляются при углубленной работе с XML:
Их сложно писать и понимать.
Синтаксис определений DTD отличается от языка XML. Он является расширенной формой Бэкуса-Науэра (Extended Backus Naur Form, EBNF), и многие находят его трудным для чтения и использования. Предлагаемые схемы XML фактически, используют язык XML для описания определяемых ими языков, что устраняет необходимость изучения языка EBNF для их чтения и записи.
Программная обработка их метаданных затруднена.
Использование языка EBNF, кроме того, затрудняет автоматизированную обработку метаданных в определениях DTD. Разумеется, для DTD существуют специальные анализаторы. Он должен загрузить и прочитать DTD, после чего сможет проверить соответствующий документ на допустимость. К сожалению, не предусмотрена возможность обратиться к DTD из программы, использующей модель DOM. Объектная модель не позволяет получить доступ к метаданным словаря, написанным на языке EBNF. Анализатор прочитает DTD и сохранит его информацию для себя. Безусловно, было бы удобно, если бы DTD было написано на языке XML, так что мы могли бы исследовать их так же легко, как мы исследуем документы, написанные в соответствии с содержащимися в них правилами. Такая возможность позволила бы при помощи DOM изучить структуру обнаруженных нами словарей и даже модифицировать их правила проверки допустимости в соответствии с теми или иными условиями программы.
Они не являются расширяемыми и не поддерживают пространства имен.
Определения DTD представляют собой фиксированную сущность. В них должны существовать все правила словаря. Все, что вам может понадобиться, вы размещаете в вашем словаре. Не создавая внешних объектов, вы не сможете использовать имена из других источников.
Создание и обслуживание ваших собственных подмножеств деклараций разметки станет значительно более удобным в результате использовании ссылки на существующее определение. Вы не можете позволить авторам документа включать в него что-нибудь интересное впоследствии, если соответствующее определение отсутствует в DTD.
Конечно, не всегда надо предоставлять авторам документов такую свободу, но было бы хорошо использовать части существующей схемы при проектировании нового словаря.
Поскольку все правила словаря должны находиться в DTD, вы не можете смешивать пространства имен. Хотя при помощи пространства имен можно ввести в документ тип элемента, нельзя ссылаться на декларацию элемента в DTD. При его использовании все его элементы должны быть объявлены в DTD.
Они не поддерживают типов данных.
Одним из существенных преимуществ языка XML является то, что все документы полностью пишутся при помощи общего типа данных - текста. Задачи программирования, однако, требуют использовать и другие типы. Определения DTD предлагают не много других типов данных, что является серьезным недостатком, когда XML применяют в приложениях определенного типа
Они не поддерживают наследование.
Итак, определения DTD прекрасно позволяют определять структуры документов. Если учесть, что язык XML произошел от SGML, который также использует DTD, можно легко понять выбор этих определений в спецификации XML 1.0. Однако при использовании XML не только для разметки текста, но и в ситуациях, требующих программирования, описанные ранее ограничения становятся чрезвычайно важными.
Пространства имен
Пространства имен способны помочь пользователю в двух очень важных случаях. С их помощью можно:
совмещать документы из двух или более источников, не теряя при этом уверенности, что программа различит, из какого источника взят тот или иной элемент или атрибут;по возможности разрешит агенту пользователя доступ к дальнейшему материалу, такому как определение типа документа (DTD) или другому описанию элементов и атрибутов.
Пространство имен представляет собой совокупность некоторых величин или характеристик, которые могут быть использованы в XML-документах как имена элементов или атрибутов. Пространства имен в XML определяются унифицированным идентификатором ресурса URI (в качестве URI можно использовать адрес DTD на вашем сервере). Он позволяет каждому пространству имен быть уникальным.
Итак, для того чтобы эффективно использовать пространства имен в документе, комбинирующем элементы из различных источников, нам надо определить:
Ссылку на URI, описывающий использование элемента.Псевдоним, позволяющий понять, из какого пространства имен взят наш элемент. Этот псевдоним имеет форму префикса элемента (например, если псевдонимом для неясного элемента Book является слово catalog, то, элемент будет называться <catalog:Book>).
Пространство имен и схемы
Ранее мы описали некоторые недостатки определений DTD, они связаны:
синтаксис этих определений отличается от синтаксиса XML (конкретно, используется так называемая расширенная форма Бэкуса-Наура, Extended Backus Naur Form);эти определения не достаточно выразительны; так как каждый пользователь может создавать свои собственные теги, то вполне вероятна ситуация когда для обозначения различных вещей люди будут пользоваться одними и теми же именами элементов. Даже если значения элементов одинаковы, их возможное содержание может изменяться в зависимости от определения. Таким образом, нам необходим способ, позволяющий определять конкретные виды использования элемента, особенно, если в одном документе мы смешиваем различные виды словарей. Для решения проблемы консорциум W3C выпустил спецификацию, называемую XML Namespaces (пространством имен XML), позволяющую определить контекст элемента в пространстве имен.существуют ситуации, когда необходимо скомбинировать документы XML из разных источников, соответствующих различным определениям DTD. Например, такая ситуация возникает при описании большого объема информации, если отдельных DTD недостаточно для охвата всего объема или они трудны для понимания. Возникает она и в системах электронной коммерции при попытках объединить данные вашего делового партнера с вашими. Так же может возникнуть ситуация когда необходимо просто добавить свои настройки к уже существующей DTD для того чтобы обмениваться некоторой информацией в стандартном формате. К сожалению, рекомендация XML не предоставляет способа совмещения нескольким DTD в одном документе без их модификации или создания нового DTD (используя внешние ссылки).
В данной главе рассматриваются следующие два понятия - пространство имен и схемы XML. Пространства имен позволяют разработчикам XML разбивать сложную проблему на небольшие фрагменты и объединять несколько словарей в одном документе для полного ее описания. С помощью схем проектировщики словарей создают более точные определения, чем это было возможно в DTD, причем делают это, используя синтаксис XML.
Эти два инструмента помогают решать сложные задачи, возникающие при использовании XML. Пространства имен и схемы позволяют проектировщикам и программистам XML:
Лучше организовывать словари для решения сложных проблем;Сохранять сильную типизацию данных при преобразованиях в XML и из него;Более точно и гибко описывать словари, чем это было возможно в случае DTD;Читать правила словаря на языке XML, осуществляя доступ к его определениям без усложнения анализатора.
Ресурсы
Ресурсом может быть любая ощутимая сущность в концептуальном домене, на которую можно сослаться по идентификатору URI, в любом объеме - от целого сайта до одного элемента на странице HTML или XML. Это может быть даже объект, недоступный в сети Web, например, напечатанная книга.
Ресурсы типизированы; для определения категорий, из которых берутся специфические экземпляры ресурсов, используется система классов. Поддерживается наследование классов, так что разработчик может определить уровень описания от общего до узко специфического.
Схемы
DTD фактически представляют собой разновидность схемы. Однако, говоря о схемах, разработчики XML, как правило, имеют в виду замену DTD, написанную в соответствии с синтаксисом XML. В принципе, схемы можно считать механизмом создания ограничений, так как, хотя в них объявляются допустимые элементы или атрибуты, мы ограничиваем для пользователя выбор тегов и модели содержания.
Обычно схемы можно считать метаданными, или данными о данных, при разработке схем учитываются не только определения словаря, но и разъяснения связей между определенными типами данных.
Чтобы заменить определения DTD, надо предоставить, по крайней мере, те же возможности, которые предоставляют эти определения. Необходимо определять природу и структуру документов XML. Как и DTD, схемы представляют собой описание компонентов и правил словаря XML. Однако схемы уточняют DTD, позволяя точнее выражать некоторые концепции словаря. Кроме того, в схемах сделано несколько радикальных изменений. Используемый в них синтаксис полностью отличается от DTD. Они позволяют использовать имена из других схем, что решает проблему проверки допустимости. Они позволяют типизировать данные элементов и атрибутов. Можно сказать, схемы являются лучшим решением проблемы определения словарей.
Язык XML хорошо согласуется с определениями DTD. В то же время их активно пытаются усовершенствовать. Было выдвинуто множество предложений (некоторые из них доступны на сайте W3C как примечания), они, как это ни парадоксально, не помогают, а затрудняют принятие рекомендации, которая отражала бы наиболее распространенные особенности, требуемые от схем. В частности, многие разработчики настаивают на поддержке сильной типизации, возможности проверять допустимость документа на основе нескольких пространств имен одновременно и периодического использования синтаксиса XML.
Смешение словарей
При проектировании словаря может иметь смысл разбить глобальную проблему на несколько составных частей. Для этого необходимы способы сегментации большой проблемы на несколько словарей. Однако при этом настоящая проблема, которую нужно решить, связана с объединением отдельных DTD в теле одного документа. Данная проблема может возникнуть и в случае если вы, например, работаете на корпорацию в которой скорее всего уже существует набор определений DTD и их использование может существенно облегчит работу, потому что они описывают проблему так, как ее понимают другие. Часто также бывает полезно повторное использование определений DTD, т.е. использование общих конструкций из ранее созданных определений DTD. Если вы разрабатываете приложение, которое должно связываться с программами внешнего партнера, вам, практически, ничего не остается, кроме повторного использования существующих концепций. Имеющиеся определения DTD составляют общепринятый язык, на котором надо говорить, чтобы быть понятым. Если концепция уже существует, надо работать так, чтобы быть понятым в терминах этой концепции.
Когда вы используете полезные для вас определения из DTD других разработчиков или комбинируете сегментированные DTD для создания документа, описывающего сложную проблему, если в ваших документах используются элементы с одинаковыми именами, вы рискуете столкнуться с проблемой неясности и коллизии имен.
Проблема еще больше обостряется при использовании экземпляров имен из нескольких DTD. В этом случае мы не знаем, какой элемент, на какое определение DTD ссылается, такая проблема правильно оформленных документов называется неясностью. Более того, если имена из документа требуют проверки допустимости, мы можем очень сильно "запутать" наше приложение. Это проблема называется коллизия имен.
что ресурсы имеют свойства, которые
Говорят, что ресурсы имеют свойства, которые определяют и описывают их. На свойства налагаются ограничения, которые определяют их форму. Эти ограничения уточняют типы значений, которые могут быть присвоены свойству, и диапазон буквенных значений данного типа, которые могут быть выбраны.
Усилия по созданию схем
В связи с необходимостью создания языка схем, призванного заменить и расширить DTD, было выдвинуто множество предложений. В их число входят:
RDFXML-DataDocument Content Description (DCD)Schema for Object-Oriented XML (SOX)Document Definition Markup Language(DDML, ранее известный как XSchema)
Ни один из этих проектов не был формально поддержан консорциумом W3C, тем не менее, каждый из них рассматривается консорциумом в процессе его работы над схемами XML.
Утверждения
Описав имена и структуры при помощи ресурсов и свойств, можно сформировать утверждения о концептуальном домене. Для этого составляются триплеты из ресурсов (подлежащих), свойств (сказуемых) и значений (дополнений). В специфических утверждениях значения могут быть литералами, а для мощных утверждений, охватывающих целые классы, они представляют собой ресурсы.
Может показаться, что для выполнения простого действия приходится затратить много усилий, но благодаря синтаксису можно делать утверждения о классах. Сделав в схеме больше утверждений, вы явным образом определите больший объем знаний о домене проблемы.
RDF - чрезвычайно мощный язык, допускающий использование выразительных и гибких утверждений. Он решает проблему недостаточной поддержки сильной типизации в DTD, сильная типизация является центральной особенностью схемы RDF. Проектирование такой схемы, будучи трудоемким процессом, предполагает декларацию большого количества классов и свойств. Хотя возможность делать значимые утверждения была высоко оценена, она, вероятно, еще более мощная, чем это нужно для описания словарей XML.
Сказанное не означает, что эта возможность не требуется и в других ситуациях. Утверждения RDF позволяют формально описать факты в формате, поддающемся чтению компьютером. Как правило, разрабатываемые нами, словари XML неявным образом полагаются на общее понимание образующих их концепций окружающего нас реального мира. С помощью утверждений RDF мы, по крайней мере, теоретически, можем ввести достаточно информации, чтобы приложение само могла обнаружить дополнительные сведения о словаре. Это позволяет более эффективно использовать новый словарь и определять, в каких случаях он может быть применен к решаемой нами проблеме.
Однако для проектировщика, решающего задачи определения имен, структуры и связей, это может оказаться слишком большой нагрузкой.
XML-Data
Область применения стандарта XML-Data является более умеренной по сравнению с RDF.
Стандарт XML-Data различает синтаксические и концептуальные схемы. Хотя в обеих используется один и тот же язык, они освещают размечаемые нами данные с разных сторон.
Синтаксические схемы - это набор правил, предоставляющих процесс описания документов с помощью разметки; определения DTD являются примеров таких синтаксических схем. Синтаксические схемы XML-Data налагают сходные с DTD ограничения на структуру словаря.
Концептуальные модели описывают связи между понятиями или объектами и, как таковые, они идеальны для моделирования реляционных баз данных. При помощи схем XML-Data можно установить связи, основанные на том, что книги содержат заголовки и цены. Это делается способом, отличающимся от синтаксиса любого документа XML. Новый стандарт предназначается для того, чтобы расширить область применения языка XML, включив в него информацию о реляционных базах данных. Главные связи, выраженные ключами в реляционных базах данных, можно формально выразить также и в схемах XML-Data.
XML Data содержит интересные возможности, делающие его более мощным чем DTD:
Использование языка XML
В языке XML-Data для конструирования схем используется словарь XML, что дает пользователям возможность читать и записывать схемы, не осваивая предварительно новый синтаксис. Это также дает возможность изучать схему или динамически создавать новую при помощи модели DOM и существующих анализаторов.
Типизация данных
Язык XML-Data поддерживает сильную типизацию элементов и атрибутов, снимая, таким образом, одно из основных возражений против DTD. Это могут быть базовые типы, определенные в пространстве имен типов данных, или комплексные пользовательские типы, содержащиеся в схеме, предоставляемой проектировщиком. Приложение больше не должно понимать тип данных элемента или атрибута и перед использованием данных преобразовывать строки или текст в соответствующий формат. Требуемую информацию можно явным образом определить в схеме, а анализаторы выполнят преобразование по желанию приложения.
Ограничения на допустимые значения
Язык XML- Data позволяет налагать ограничения на диапазон значений, принимаемых элементами и атрибутами, такие как минимальное и максимальное значения. Эта возможность часто бывает, полезна при проверке допустимости документов XML.
Наследование типов
Механизмом, позволяющим повторно использовать элементы, является поддерживаемое языком XML Data наследование типов. Он позволяет выявлять и расширять элементы при описании объектов проблемы, решить которую мы пытаемся с помощью XML. Мы можем написать, например, некоторые общие надтипы, а затем уточнять их в более специфические классы элементов, добавляя или заменяя новые члены в декларации надтипа. В определениях DTD таким же способом используются сущности (entities), но наследование типов формализует процесс. Не имея формальной семантики, сущности могут быть использованы неверно, настолько, что это затруднит, а не облегчит работу пользователя. Формальный механизм наследования дает возможность повторного использования, сохраняя при этом некоторый контроль над реализацией этой возможности.
Открытые и закрытые модели содержания
Еще одной мощной возможностью языка XML-Data являются так называемые открытые и закрытые модели содержания. Классическое определение DTD представляет собой закрытую модель. Соответствующие ей документы должны придерживаться правил и не могут содержать ничего, что не соответствует правилам, поскольку все они должны быть описаны в DTD.
Если схема открыта, то соответствующие ей документы могут содержать и другую информацию, не объявленную в DTD. Соответствующая схеме часть документа должна подчиняться заложенным в ней правилам, но мы можем включать в него и другие пункты без ограничений со стороны текущей схемы. Эти пункты могут быть описаны в другой схеме, а могут быть, вообще, никак не ограничены. Можно использовать специальные значения. С точки зрения нашей дискуссии, более важно то, что документы открытой модели представляют собой способ, позволяющий смешивать пространства имен.Фрагмент информации, соответствующий одной схеме, можно включить в середину документа, соответствующего другой. Более того, можно явным образом объявить, что для конкретных элементов используется открытая или закрытая модель содержания. Для этого существует атрибут content, значением которого по умолчанию является open.
Расширенные конструкции ID и IDREF
В языке XML-Data конструкции ID и IDREF расширяются отношениями. В отношении один элемент используется в качестве ключа или индекса для содержания другого элемента. Это непосредственно применимо к моделированию первичных и внешних ключей в реляционных базах.
XML Schema
Все, что можно было описать с помощью DTD, содержится в части стандарта XML Schema, посвященного структурам. Поскольку схемы пишутся в соответствии с синтаксисом XML, структуры ссылаются на конструкции на этом языке, при помощи которых можно определять разметку. Это означает, что структуры представляют собой еще одно приложение XML (словарь XML для описания классов документа XML) и как таковое могут использовать схемы для описания самих себя.
Итак, раздел схем спецификации представляет собой ту ее часть, в которой определены элементы и атрибуты для описания схем. Что более важно, в этой части описана модель содержания для элементов. Такая модель явным образом определяет допустимую внутреннюю структуру элементов. Структуры являются сердцем схем XML.
В окружающем нас мире широко используются концепции чисел, строк и множеств, так что написанные на современных языках программы поддерживают большое количество тщательно проработанных систем встроенных типов данных и процедуры по определению новых типов. Добавление типов данных в проект XML Schemas станет важным подспорьем для программистов, использующих XML при работе с данными в своих приложениях. Такая поддержка типов данных предусматривает возможность проверять допустимость значения в документе, а также осуществлять преобразование из текстовой формы во встроенный тип при обработке документа XML. Таким образом, чтобы использовать документы XML в качестве основы для интеграции программ и систем, необходимо иметь возможность перехватывать (определять) типы данных размечаемой нами информации.
Это обеспечивает вторая часть спецификации XML Schemas, носящая название XML Schemas: Datatypes. Она позволяет не только перехватывать базовые типы данных, но и записывать ограничения, налагаемые на данные в домене нашей проблемы. Она позволяет записывать числовые границы, множества и упорядоченные списки, а также создавать маски для допустимых строковых представлений наших данных.
Типы данных схем имеют набор четких значений, называемый пространством значений (value space). Он представляет собой абстрактную коллекцию значений, которые может принимать тип. Например, множество целых чисел является пространством значений для типа integer. Это пространство характеризуется ограничивающими свойствами и операциями над значениями в нем.
Часть XML Schema: Datatypes целиком посвящена вопросам определения пространств значений, а затем перечислению ограничивающих свойств типа. Он содержит множество примитивных типов данных и предоставляет механизм генерации новых типов на их основе. В проект входит большое количество таких генерированных типов, находящих широкое применение, но его составители приветствуют создание собственных типов, предназначенных для использования в конкретном приложении.
<