Атрибуты
Для того чтобы при определении элемента задать какие-либо параметры, уточняющие характеристики данного элемента используются атрибуты.
Атрибуты состоят из пары "название" = "значение", которую можно задавать при определении элемента в начальном тэге. Слева и справа от символа равенства можно оставлять пробелы. Значение атрибута указывается в виде строки, заключенной в одинарные или двойные кавычки.
Любой тэг может иметь атрибут, если этот атрибут определен.
В случае использования атрибута элемент принимает следующую форму:
<имя_тега атрибут = "значение"> содержимое тега </имя_тега>
Пример:
<p ALIGN="CENTER"> текст выравнивается по центру </p>
В одном открывающемся теге может содержаться несколько атрибутов, например:
<FONT SIZE = 7 color = "RED"> Указан размер и цвет текста </FONT>
Что такое XML
Свое название расширяемый язык разметки XML (Extensible Markup Language) получил по той причине, что в нем нет фиксированного формата, как в HTML. В то время как язык HTML ограничивается набором твердо закрепленных тегов, пользователи XML могут создавать свои собственные тэги, которые бы отвечали тематики документа. Таким образом, XML - это метаязык. Этот язык используется в качестве средства для описания грамматики других языков и контроля за правильностью составления документов.
Документ XML выглядит во многом похожим на HTML. В XML существуют открывающие, закрывающие и пустые тэги. Однако, в отличие от HTML, правила относительно тегов более строгие, например, смысл тега зависит от регистра, а каждый открывающий тег должен во всех случаях иметь парный закрывающий тег. Теги в документе могут быть вложены друг в друга. Теги начала и конца элемента являются основными используемыми в XML разметками, но ими дело не исчерпывается. Так же как и в HTML тэги могут иметь атрибуты, причем количество атрибутов зависит от фантазии автора. Документы XML могут содержать ссылки на другие объекты. Ссылки представляют собой строку, начинающуюся с амперсанта и заканчивающуюся точкой с запятой. Ссылки позволяют, в частности, вставить в документ специальные символы, включение которых самих по себе могло бы сбить с толку программу разбора. К тому же ссылки могут ссылаться на определенные автором разделы текста в том же самом или в другом документе. Для того чтобы используемые вами в документе теги понимали и другие необходимо составить определения типов документов (Document Type Definition, DTD). Хранимые в начале файла XML или внешним образом в виде файла, эти определения описывают информационную структуру документа. DTD перечисляют возможные имена элементов, определяют имеющиеся атрибуты для каждого типа элементов и описывают иерархию элементов. Сам XML документ не несет информацию о том как находящиеся в нем данные должны отображаться на экране, за это отвечает таблица стилей. Таким образом, в документе имеется разграничение между оформлением и содержанием.
Подводя итоги можно сказать, что основными достоинствами XML являются:
авторы XML-документов могут создавать свои собственные тэги, относящиеся к содержанию документа. XML несет информацию только о структуре и смысле документа, оставляя форматирование элементов таблице стилей. Одним из важных достоинств XML является его способность объединять несколько ХМL - документов в один большой документ.
История развития языков разметки.
Понятие гипертекста было введено В.Бушем в 1945 году а, начиная с 60-х годов, стали появляться первые приложения, использующие гипертекстовые данные. Однако основное развитие данная технология получила, когда возникла реальная необходимость в механизме объединения множества информационных ресурсов, обеспечения возможности создания, просмотра нелинейного текста.
В 1986 году ISO был утвержден универсальный стандартизированный язык разметки (Standardized Generalized Markup Language). Этот язык предназначен для создания других языков разметки, он определяет допустимый набор тэгов, их атрибуты и внутреннюю структуру документа. Таким образом имеется возможность создавать свои собственные тэги, связанные с содержанием документа. Таким образом становится, очевидно, что такие документы трудно интерпретировать без определения языка разметки, которое хранится в определении типа документа (DTD - Document Type Definition). В DTD сгруппированы все правила языка в стандарте SGML. Другими словами в DTD описывается связь тегов между собой и правила их применения. Причем для каждого класса документов определяется свой набор правил, описывающих грамматику соответствующего языка разметки. Таким образом, только при помощи DTD можно проверить правильность использования тегов а, следовательно, его нужно посылать вместе с SGML-документом или включать в документ.
В то время кроме SGML существовали еще несколько конкурирующих между собой подобных языков, однако популярность - HTML, который является одним из его потомков - дала SGML неоспоримое преимущество перед своими собратьями.
С помощью SGML можно описывать структурированные данные, организовывать информацию, содержащуюся в документах, представлять эту информацию в некотором стандартизованном формате. Но из-за своей сложности, SGML использовался, в основном, для описания синтаксиса других языков, и немногие приложения работали с SGML-документами напрямую. SGML обычно применяется лишь в крупных проектах, например, для создания единой системы документооборота крупной фирмы.
Гораздо более простой и удобный, чем SGML, инструкции HTML, в первую очередь, предназначены для управления процессом вывода содержимого документа на экране. Язык HTML как способ разметки технических документов был создан Тимом Бернерсом-Ли (Tim Berners-Lee) в 1991 году специально для научного сообщества. Первоначально он был всего лишь одним из SGML-приложений.
Не смотря на то, что единственное, что умеет HTML - классифицировать части документа и обеспечивать его правильное отображение в браузере, он является самым популярным языком разметки. Это связано с тем, что HTML достаточно легок для изучения. Все, что от вас требуется, - изучить команды HTML. DTD для HTML хранится в браузере. К тому же надо заметить, что HTML спроектирован для работы на самых разных платформах. Но у него есть ряд существенных ограничений:
HTML имеет фиксированный набор тэгов, и данный набор нельзя расширить или изменить;теги языка HTML показывают только, как должны быть представлены данные, внешний вид документа. HTML не несет информации о значении содержания, заключенного в тэгах, структуре документа;
В 1996 общественной организацией World Wide Web Consortium (W3C) началась разработка XML (Extensible Markup Language) который стал золотой срединой между языками SGML и HTML. Язык XML позволяет разработчику создавать свои собственные теги, но в отличие от SGML он достаточно прост.
На основе языка XML был создан язык разметки для беспроводных устройств WML. Данный язык позволяет описать пользовательский интерфейс на устройствах с ограниченными возможностями представления данных, например, мобильных телефонах.
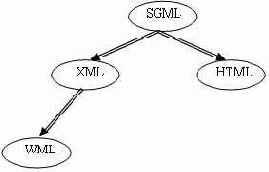
Все представленное множество языков разметки удобно для наглядности представить в виде следующего "генеалогического дерева" языков разметки:
Язык XML в качестве данных
Разметка ХМL отражает содержание документа, его можно использовать как универсальный формат в любых приложениях. Таким образом, XML-файл может быть не только воспроизведен на браузере, но, поскольку XML интегрирован в ряд других приложений, с его помощью можно предоставить пользователю данные для их дальнейшей обработки. XML, как язык разметки документов, приобретает все большую популярность в качестве формата хранения различных материалов. Однако XML не всегда удобен для хранения больших групп записей, так как кроме всего прочего необходимо хранить и описание тегов. В данном случае обычно используют традиционную базу данных, а по мере необходимости преобразовывать ее содержимое в XML.
Языки разметки. Введение в XML
Язык разметки (markup languages) - это набор специальных инструкций, называемых тэгами, предназначенных для формирования в документах какой-либо структуры и определения отношений между различными элементами этой структуры. Другими словами разметка показывает, какая часть документа является заголовком, какая подзаголовком, что следует считать именем автора и т. д. Разметка разделяется на стилистическую разметку, структурную и семантическую.
Как появился XML
Разработка XML началась в 1996 году. Консорциум World Wide Web (W3C) выделил средства группе экспертов по языку SGML, возглавляемой Джоном Боузэком (Jon Bosak) из компании Sun Microsystems, для создания подмножества языка SGML, которое могло бы быть принято Web-сообществом. В результате работы несущественные возможности SGML были удалены, в результате чего язык, разработанный таким образом, оказался значительно более доступным, чем оригинал. В 1998 году консорциум выпустил спецификацию XML версии 1.0. Она постоянно совершенствуется, последний вариант спецификации всегда находится по адресу http://www.w3c.org/TR/rec-xml.
Необходимо отметить, что язык XML был разработан таким образом, что любой действительный документ XML является действительным документом SGML.
Семантическая разметка
Семантическая разметка информирует о содержании данных. Примера данного типа разметки являются теги <TITLE> </TITLE>(имя документа), <CODE> </CODE>(код, используется для листингов кода), <VAR> </VAR>(переменная), <ADDRESS> </ADDRESS>(адрес автора).
Основными понятиями любого языка разметки являются теги, элементы и атрибуты.
Стилистическая разметка
Стилистическая разметка отвечает за внешний вид документа. Например, в HTML к данному типу разметки относятся такие теги как <I> </I> (курсив), <B> </B> (жирный), <U> </U> (подчеркивание), <S> </S> (перечеркнутый текст) и т.д.
Структурная разметка
Структурная разметка задает структуру документа. В HTML за данный тип разметки отвечают, например, теги <P> </P>(параграф),<H?> </H?>(заглавие), <DIV> </DIV> (секция) и т.д.
Тэги и элементы.
Значения понятий тэги и элементы часто путают.
Тэги, или, как их еще называю, управляющие дескрипторы, служат в качестве инструкций для программы, производящей показ содержимого документа на стороне клиента как поступить с содержимым тега. Для того чтобы выделить, тег, относительно основного содержимого документа используются угловые скобки: тег начинается со знака "меньше" (<) и завершается знаком "больше" (>), внутри которых помещаются название инструкций и их параметры. Например, в языке HTML тег <I> указывает на то, что следующий за ним текст должен быть выведен курсивом.
Элемент - это тэги в совокупности с их содержанием. Следующая конструкция является примером элемента:
<I> Это текст выделен курсивом </I>.
Элемент состоит из открывающего тега (в нашем примере это тег <I>), содержимого тега (в примере это текст "Это текст, выделен курсивом") и закрывающего тега(</I>), правда иногда в HTML, закрывающий тег можно опустить.
Взаимодействие с машиной
Поскольку XML-файлы несут информацию о своем содержании, машинные пользовательские агенты способны обрабатывать информацию, помещенную в файл. Это означает, что в частном случае применения поисковых машин они обеспечивают значительно более точные результаты по запросам. В то время как HTML стал форматом представления, XML действует в качестве общепринятого синтаксиса, позволяя значительно большему числу машинных пользовательских агентов использовать хранимые в XML файлах данные для различных целей.

<
Анализаторы.
Помимо определения синтаксиса XML, в рекомендации W3C описан так же процессор или анализатор XML. Существуют два типа анализаторов:
non-validating (не проверяющий на допустимость) - анализатор просто проверяет, чтобы объект данных был правильно оформленным документом XMLvalidating (проверяющий на допустимость) - с помощью определения DTD анализатор проверяет допустимость формы и содержания правильно оформленного документа XML
Некоторые анализаторы поддерживают оба типа, при этом в их конфигурации имеется возможность переключаться на один из них, в зависимости от того, надо ли проверять допустимость документа.
Атрибут xml:lang
Атрибут xml:lang используется для идентификации языка, который использовался при записи содержимого и значений атрибутов любого элемента. Данный атрибут пригодится в международных документах XML.
Атрибут xml:lang как и все остальные атрибуты необходимо продекларировать в DTD. Данный атрибут может принимать значения определенные в документе IETF (Internet Engineering Task Force) RFC 1766: Тэги для идентификации языков, редактор H. Alvestrand. 1995. (http://www.ietf.org/rfc/rfc1766.txt.) или наследующих его стандартах IETF. Значение атрибута применяется не только к содержащему его элементу, но и ко всем его потомкам и атрибутам.
Как и в случае xml: space, приложение вовсе не обязано реагировать на атрибут xml: lang.
Атрибут xml:space
С помощью атрибута xml:space можно указать приложению на необходимость сохранять пустые пространства. Впрочем, фактические действия приложения зависят от самого приложения - в рекомендациях XML по этому поводу нет никаких требований. Атрибут xml: space будет полезен при моделировании данных XML.
Атрибут xml:space может принимать значения "preserve" и "default". Значение "preserve" предписывает сохранять пробельные символы в неприкосновенности. Значение "default" оставляет пробельные символы на усмотрение программы-обработчика.
Значение атрибута применяется не только к содержащему его элементу, но и ко всем его потомкам.
Атрибуты.
Открывающие теги либо теги пустых элементов в XML могут содержать атрибуты, представляющие собой пару имя=значение. В одном открывающем теге разрешается использовать только один экземпляр имени атрибута. Атрибуты могут содержать ссылки на объекты, ссылки на символы, текстовые символы. В отличие от языка HTML, в XML значения атрибутов обязательно надо заключать в апострофы ('), либо в кавычки ("). Таким образом, атрибут может быть записан в одном из двух форматов:
имя_атрибута="значение_атрибута" имя_атрибут='значение_атрибута'.
Атрибуты используются, для того чтобы связать некоторую информацию с элементом, а не просто включить ее в содержание последнего. Однозначного ответа на вопрос что лучше выбрать элемент или атрибут не существует. Каждый выбирает то, что ему больше нравиться. Атрибуты удобно использовать для описания простых значений или для указания типа элемента. Например, мы можем ввести в открывающий тег <city> атрибут type( который может принимать одно из значений: город, поселок, деревня) тогда данный тег может выглядеть следующим образом:
<city type="город"> Новосибирск </city>
Помимо атрибутов, которые можно определять самим, существуют еще два специальных атрибута, чьи роли в языке XML фиксированы. В рекомендациях XML 1.0 определены два специальных атрибута - xml:space и xml:lang.
Древовидные анализаторы.
Одной из самых распространенных структур в конструировании программного обеспечения является простое иерархическое дерево. Все правильно оформленные данные XML должны представлять собой такое дерево, и потому для путешествия по узлам документа, поиска его содержания и/или редактирования можно использовать распространенные хорошо разработанные алгоритмы. Эти алгоритмы в течение десятилетий разрабатывались и использовались в академической и коммерческой среде. Использующие этот подход анализаторы XML, как правило, соответствуют предложенной консорциумом W3C объектной модели документа (DOM).
Имена.
В языке XML все имена должны начинаться с буквы, символа нижнего подчеркивания (_) или двоеточия (:) и продолжаться только допустимыми для имен символами, а именно они могут содержать только буквы, входящие в секцию букв кодировки Unicode, арабские цифры, дефисы, знаки подчеркивания, точки и двоеточия. Однако имена не могут начинаться со строки xml в любом регистре. Имена, начинающиеся с этих символов, зарезервированы для использования консорциумом W3C. Нужно помнить что так как буквы не ограничены исключительно символами ASCII, то в именах можно использовать слова из родного языка.
Инструкции по обработке.
Инструкции по обработке содержат указания программе анализатору документа XML. Инструкции по обработке заключаются между символами <? и ?>. Сразу за начальным вопросительным знаком записывается имя программного модуля, которому предназначена инструкция. Затем, через пробел, идет сама инструкция, передаваемая программному модулю. Сама инструкция это обычная строка, которая не должна содержать набор символов "?>", означающий конец инструкции. Примером инструкции по обработке может служить строка объявления XML:
<?xml version="1.0" encoding="windows-1251"?>
Эта инструкция предназначена программе, обрабатывающей документ XML. Инструкция передает ей номер версии и кодировку, в которой записан документ.
Элементы.
Документ XML состоит из элементов. Элемент начинается открывающим тегом, затем идет необязательное содержимое элемента, после чего записывается закрывающий тег (в отличие от HTML наличие закрывающего тега обязательно, исключением являются элементы без содержания, так называемые пустые элементы, которые могут быть записаны в сокращенной форме). В качестве содержимого элемента могут выступать другие элементы, символьные данные, ссылки на символы, ссылки на сущности, комментарии, разделы CDATA, инструкции по обработке.
Эпилог
В эпилог XML могут входить комментарии, инструкции по обработке и/или пустое пространство.
В языке XML не определен индикатор конца документа, большинство приложений для этой цели используют завершающий тег корневого элемента документа. Таким образом, встретив, завершающий тег корневого элемента, , скорее всего, приложение закончит обработку документа, и эпилог обработан не будет.
Комментарии.
Если надо вставить в текст документа комментарий либо сделать какой-то фрагмент "невидимым" для программы-анализатора, то его оформляют следующим образом:
<!--…текст комментария…-->
Комментарии могут появляться в любом месте документа вне другой разметки.
Текст комментария это любая строка символов со следующими ограничениями:
в комментарии нельзя записывать два дефиса подряд;комментарий нельзя завершить дефисом.
Открывающие теги.
Открывающий тег начинается со знака "меньше" (<) и завершается знаком "больше" (>), внутри которых помещаются имя элемента:
<имя_элемента>.
Правильно оформленные и верные документы.
Все объекты данных (документы), соответствующие спецификации XML, называются правильно оформленными (well-formed) документами. Правильно оформленный документ XML:
содержит один или несколько элементов (ограниченных открывающим и закрывающим тегами), правильно вложенными друг в друга; существует только один корневой элемент, который содержит все остальные элементы документа.все элементы образуют простое иерархическое дерево, так что единственным непосредственным отношением между элементами является отношение типа "родитель-потомок".
Любой анализатор XML, столкнувшись в данных XML с конструкцией, которая не является правильно оформленной, должен сообщить приложению об этой ошибке, после чего анализатор может продолжить обработку документа, пытаясь найти остальные ошибки, но он уже не будет передавать данный приложению.
Концепция правильно оформленных документов позволяет использовать данные XML без необходимости конструировать внешние описания данных и ссылаться на них.
Однако кроме проверки на формальное соответствие грамматике языка, в документе могут присутствовать средства контроля над содержанием документа: DTD - определения (Document Type Definition) и схемы данных (Semantic Schema). Прочитав формализованное описание и узнав из него схему документа, программа-анализатор может проверить соответствие каждого документа - его схеме и сделать вывод, верен этот документ или нет. Для того, чтобы обеспечить проверку корректности XML- документов, необходимо использовать анализаторы, производящие такую проверку.
Пролог XML- документа.
Документ XML начинается с пролога. В прологе содержатся некоторые указания, предназначенные для анализатора XML и приложений.
Пролог состоит из нескольких частей:
необязательное объявление XML (XML Declaration) которое заключено между символами <?...?>. Объявление содержит: пометку xml и номер версии (version) спецификации XML;указание на кодировку символов (encoding), в которой написан документ (по умолчанию encoding="UTF-8");параметр standalone который может принимать значения "yes" или "no" (по умолчанию standalone="yes"). Значение "yes" показывает, что в документе содержатся все требуемые декларации элементов, a "no" - что нужны внешние определения DTD.
Все это вместе может выглядеть следующим образом:
<?xml version ="1.0" encoding="windows-1251" standalone="yes"?>.
Важно отметить, что в объявлении XML только атрибут version является обязательным, все остальные атрибуты могут быть опущены и, следовательно, принимать значения по умолчанию. Так же нужно помнить, что все эти атрибуты следует указывать только в приведенном выше порядке.
комментарии.команды обработки. символы пустых пространств.необязательное объявление типа документа, DTD (Document Type Declaration) которое заключено между символами <!DOCTYPE...> и может занимать несколько строк. В этой части объявляются теги, использованные в документе, или приводится ссылка на файл, в котором записаны такие объявления.
После объявление типа документа так же могут следовать комментарии, команды обработки и символы пустых пространств.
Поскольку все эти части необязательны, пролог может быть опущен.
Пространства имен XML
Поскольку в разных XML-документах могут встретится одни и те же имена тегов и их атрибутов, имеющие совершенно разный смысл, надо иметь возможность их как-то различать. Для этого имена тегов и атрибутов снабжают кратким префиксом, который отделяется от имени двоеточием. Префикс имени связывается с идентификатором, определяющим пространство имен (namespace). Все имена тегов и атрибутов, префиксы которых связаны с одним и тем же идентификатором, образуют одно пространство имен, в котором имена должны быть уникальны. Префикс и идентификатор пространства имен определяются атрибутом xmlns следующим образом:
<ns:root_element_name xmlns:ns = "http://URI_namespace">
В дальнейшем имена тегов и атрибутов, которые мы хотим отнести к пространству имен "http://URI_namespace", снабжаются префиксом ns, например:
<ns:city ns:type="город">Новосибирск</ns:city>.
Атрибут xmlns может появиться в любом элементе XML, а не только в корневом. Определенный им префикс можно применять в том элементе, в котором записан атрибут xmlns, и во всех вложенных в него элементах. Более того, в одном элементе можно определить несколько пространств имен. Во вложенных элементах пространство имен можно переопределить, связав префикс с другим идентификатором. Появление имени тега без префикса в документе, использующем пространство имен, означает, что имя принадлежит пространству имен по умолчанию. Префиксы, начинающиеся с символов xml с любым регистром букв, зарезервированы за самим языком XML.
Имя вместе с префиксом называется расширенным или уточненным именем. Часть имени, записанная после двоеточия, называется локальной частью имени.
Идентификатор пространства имен должен иметь форму URI. Адрес URI не имеет никакого значения и может не соответствовать никакому действительному адресу Интернета. В данном случае URI можно рассматривать как уникальную строку символов, идентифицирующую пространство имен.
По правилам SGML и XML, двоеточие может применяться в именах как обычный символ, поэтому любая программа, "не знающая" пространства имен, анализируя документ, рассматривает уточненное имя как обычное уникальное имя. Отсюда следует, в частности, что в объявлении типа документа (Document Type Declaration) нельзя опускать префиксы имен.
Пустые элементы.
Если в содержимом элемента нет ни одного символа, даже пробела, то закрывающий тег можно не записывать. В этом случае открывающий тег должен заканчиваться символами "/> ".
Таким образом, тег пустого элемента начинается со знака "меньше" (<) за которым следует имя элемента и завершается знаками "косая черта" (/) после которой идет знак "больше" (>):
<имя_элемента/>.
Пустые пространства.
В языке XML пустым пространством считаются только четыре символа: горизонтальная табуляция (HT), перевод строки (LF), возврат каретки (CR), символ пробела ASCII. В стандарте Unicode также определено несколько других типов пустых пространств, но ни один из них не считается таковым в контексте разметки XML.
Спецификация XML требует, чтобы анализатор передавал все символы, в том числе и символы пустых пространств в содержании элемента, приложению. Символы же пустых пространств в тегах элементов и значениях атрибутов могут быть удалены.
Секция CDATA.
Секция CDATA используется, для того чтобы задать область документа, которую при разборе анализатор будет рассматривать как простой текст, игнорируя любые инструкции и специальные символы. Программа-анализатор не разбивает секцию CDATA на элементы, а считает ее просто набором символов. В отличие от комментариев, содержание данной секции не игнорируется, а передается без изменений на выход программы анализатора, благодаря чему его можно использовать в приложении.
Секция CDATA начинается со строки <![CDATA[ после которой записывается содержимое секции. Завершается секция двумя закрывающими квадратными скобками и знаком "меньше":
<![CDATA[ содержание секции ]]>
Секция CDATA может содержать любую символьную строку, кроме "]]>".
Секции CDATA можно создать в содержимом любого элемента XML. На секцию налагаются следующие два ограничения:
внутри секции CDATA нельзя создать новую секцию,секции CDATA нельзя вкладывать друг в друга.
Символьные данные.
Символьные данные - это любой текст, являющийся содержанием элемента или значением атрибута. Если в содержимое элемента нужно вставить некоторые символы, которые используются в служебных целях, например знаки "больше" или "меньше" которые являются ограничителями разметки и могут быть поняты как начало или конец вложенного тега, то эти символы необходимо заменить ссылками или их числовыми кодами.
Символы.
Поскольку XML предназначен для широкого использования, символы не ограничены 7-битным набором символов ASCII. К числу символов, допустимых в языке XML, относятся три управляющих символа СО стандарта ASCII, все обычные символы этого стандарта и почти все остальные символы Unicode
Синтаксис разметки.
Для ограничения тегов в разметке XML, так же как и в HTML используются угловые скобки: тег начинается со знака "меньше" (<) и завершается знаком "больше" (>). Но необходимо помнить, что в отличие от HTML вся разметка XML чувствительна к регистру символов, это касается как имен тегов, так и значений атрибутов.
Событийно управляемые анализаторы.
Один из подходов в обработке данных XML связан с событийно управляемыми анализаторами. В этом случае анализатор осуществляет обратное обращение (call-back) к приложению для каждого класса данных XML: элементы (с атрибутами), символьные данные, команды обработки, нотации или комментарии. Приложение осуществляет всю дальнейшую обработку данных XML, полученных в результате обратных обращений, - анализатор не обслуживает древовидную структуру элемента или любые анализируемые данные. Даже для чрезвычайно больших документов анализатор XML расходует очень небольшое количество системных ресурсов; кроме того, вследствие его простого низкоуровневого доступа к данным XML, он позволяет чрезвычайно гибко работать с данными в приложении XML.
Средства тестирования анализаторов.
Два разработчика недавно создали набор тестов для анализаторов XML (XML parser benchmark tests), применив их затем к различным анализаторам в системах Linux и Solaris. Результаты этих тестов показывают, что наиболее быстрыми являются анализаторы, написанные на языке С, за ними следуют те, что написаны на языке Java, а затем - на языках сценариев (Perl и Python).
<
Ссылки на символы.
Для того что бы вставить в текст документа некоторый символ, который, например, не присутствует в раскладке клавиатуры либо может быть неправильно истолкован анализатором, используют ссылки на символы. Ссылка на символ обязательно начинается со знака "амперсанда" и заканчивается точкой с запятой.
Ссылки на символы записываются в следующем виде:
&#код_символа_в_Unicode;.
Код символа можно записать и в шестнадцатеричном виде. В этом случае перед ним ставится символ "x":
&#xШестнадцатеричный_код_символа;.
Кроме этого существуют именованные подстановки, определенные в спецификации XML, и реализованные во всех совместимых с XML анализаторах, которые делают текст документа более понятным для человека. С помощью этих именованных подстановок можно вставить в текст документа такие символы как:
| & | & |
| < | < |
| > | > |
| ' | ' |
| " | " |
Ссылки на сущности.
Ссылки на сущности позволяют включать любые строковые константы в содержание элементов или значение атрибутов. Ссылки на сущности, как и ссылки на символы, начинающиеся с амперсанда, после которого идет имя сущности и заканчивающиеся точкой с запятой:
&имя_сущности;.
Ссылки на сущности указывают программе-анализатору подставить вместо них строку символов заранее заданную в определении типа документа.
Структура XML- документа.
Любой XML-документ состоит из следующий частей:
Необязательный пролог.Тело документа.Необязательный эпилог, следующего за деревом элементов.
Рассмотрим каждую из частей более подробно.
Тело XML-документа.
Тело документа, состоит из одного или больше элементов. В правильно оформленном XML документе элементы формируют простое иерархическое дерево, в котором обязательно присутствует корневой элемент (root element) в который вложены все остальные элементы документа. Язык XML налагает на элементы чрезвычайно важное ограничение - они должны быть правильно вложены. Это позволяет достаточно легко вложить один XML- документ в другой не нарушаю структуру документа, при этом корневой элемент вложенного документа станет просто одним из элементов документа, в который он вложен. В связи с этим мы сталкиваемся с еще одним ограничением, а именно с тем, что имена элементов должны быть уникальны в пределах документа, поскольку во включенном документе такие же имена, что и во включающем могут иметь совершенно иной смысл. Для решения проблемы совпадающих имен введено понятие пространства имен.
Имя корневого элемента считается именем всего документа и указывается во второй части пролога после слова Doctype. Если определение DTD находиться внутри XML- документа, то оно помещается в квадратных скобках после имени корневого элемента:
<!DOCTYPE имя_корневого_элемента [описание DTD ]>
Но обычно определение DTD составляется сразу для нескольких XML -документов. В таком случае его удобно записать отдельно от документа и тогда вместо квадратных скобок записывается одно из слов System или Public после которого идет адрес в форме URI (Uniform Resource Identifier) файла с определением DTD. Для всех практических целей URI считается эквивалентом адреса URL, хотя в принципе это может быть любое уникальное имя. Определение DTD, например, может выглядеть следующим образом:
<!DOCTYPE root_element_name SYSTEM "DTD.dtd">
Закрывающие теги.
Закрывающий тег начинается со знака "меньше" (<) за которым следует "косая черта" (/) после которой повторяется имя элемента из соответствующего открывающего тега и завершается знаком "больше" (>):
</имя_элемента>.
При этом необходимо помнить, что каждый закрывающий тег должен соответствовать своему открывающему тегу, а так же что вложенность тэгов в XML строго контролируется, поэтому необходимо следить за порядком следования открывающих и закрывающих тэгов.
Таким образом, полностью элемент выглядит следующим образом:
<имя_элемента> содержание элемента </имя_элемента >
Ассоциирование DTD с документом XML
Для связывания декларации DTD с экземпляром документа в версии XML 1.0 предлагается специальная декларация DOCTYPE. Она должна следовать после декларации XML и предшествовать любым элементам документа. Тем не менее, между декларациями XML и DOCTYPE могут находиться комментарии и команды обработки.
Декларация DOCTYPE содержит ключевое слово DOCTYPE, за которым следует имя корневого элемента документа, а затем конструкция с декларациями содержания. Перед разъяснением этого утверждения рассмотрим пример расположения декларации DOCTYPE в экземпляре документа. Ниже приводятся первые три строчки документа XML:
.. <xml version ="1.0" ?> <!DOCTYPE root_element_name … > <root_element_name > …
Можно написать внешнее подмножество деклараций в отдельном файле DTD, включить внутреннее подмножество в тело декларации DOCTYPE или сделать то и другое. В последнем случае (смешение внутренних и внешних DTD) во внутренних DTD могут быть заданы новые декларации или переписаны те, что содержатся во внешних (по определению спецификации XML анализаторы сначала читают внутреннее подмножество, и потому содержащиеся там декларации пользуются приоритетом).
Декларации XML могут содержать атрибут standalone, принимающий только значения "yes" и "nо". Если значение атрибута равно yes, то внешние для экземпляра документа декларации не влияют на информацию, передаваемую документом использующему его приложению. Значение no показывает, что существуют внешние декларации со значениями, необходимыми для правильного описания содержания документа - например конкретные значения по умолчанию. На практике необязательный атрибут standalone используется редко. Наличие этого атрибута со значением, yes не гарантирует отсутствия внешних зависимостей любого типа. Просто внешние зависимости в этом случае не приведут к ошибке в документе, если не будут включены в обработку. Таким образом, в основном этот атрибут представляет собой знак для анализаторов и других приложений, показывающий, нужно ли им использовать какое-либо внешнее содержание.
Блок внутренней декларации разметки тега DOCTYPE состоит из левой квадратной скобки, списка деклараций и правой квадратной скобки:
<! DOCTYPE root_element_name […здесь находятся декларации внутреннего подмножества ... ]>
Внутренние DTD очень полезны, они всегда содержатся в использующем их документе и поэтому их получение анализатором не представляет проблем. Однако внутренние DTD значительно увеличивают размер документа. На практике внутренние DTD чаще всего применяются одновременно с внешними для добавления новых декларации. Если там объявлен какой-либо объект, продекларированный также и во внешнем определении DTD, приоритетом пользуется внутреннее. Это позволяет осуществлять тонкую настройку деклараций для нужд конкретных документов.
Внешние DTD в некоторых отношениях более гибкие. В данном случае декларация DOCTYPE состоит из обычного ключевого слова и имени корневого элемента, за которым следует еще одно ключевое слово SYSTEM либо PUBLIC, обозначающее источник внешнего определения DTD, а за ним - локализация этого определения. Если ключевое слово SYSTEM, DTD обязано непосредственно и явным образом находиться по указанному URL адресу.
Если внешние DTD переписываются очень часто, они начинают терять свое значение, а это признак плохого первоначального проекта.
Ключевого слова PUBLIC предназначено для хорошо известных словарей. Приложение, анализирующее документ из этого словаря, должно использовать некоторую стратегию по поиску соответствующего DTD.
Стандарт XML 1.0 допускает у декларации PUBLIC наличие как публичного URI, так и системного идентификатора. Если работающее с документом приложение или анализатор не могут найти DTD по идентификатору URI с ключевым словом PUBLIC, оно должно использовать системный идентификатор.
Недостатки и особенности определений DTD.
Описание структуры документа XML, выполненное средствами DTD имеет ряд недостатков и ограничений:
Синтаксис DTD отличается от синтаксиса XML. XML документ не может обработать проверяющий на допустимость анализатор XML, но он не обязан предоставлять связанный с этим документом DTD вызвавшему его приложению. К тому же, если мы хотим из приложения обрабатывать определения DTD, нам потребуется отдельный механизм анализа.Определения DTD представляют собой закрытые конструкции. Вся информация должна быть включена только в одно определение DTD. Это не кажется ограничением, пока нет необходимости позаимствовать декларацию или какую-либо иную полезную конструкцию из другого определения DTD.Сегментация недопустима, если не считать ситуаций, когда определение DTD можно логически сконструировать таким образом, чтобы оно включало вложенные определения DTD.В DTD практически отсутствует информация о типах данных, точном количестве повторений вложенного элемента и некоторые другие необходимые подробности.
<
Объявление атрибутов.
Атрибуты элемента объявляются после объявления самого элемента. Все атрибуты одного элемента объявляются сразу, одним списком. Список начинается с символов <!ATTLIST, после них через пробел следует имя элемента, к которому относятся атрибуты. Затем идет имя атрибута, его тип или список значений, которые он может принимать (все значения перечисляются через вертикальную черту, в скобках), признак обязательности присутствия атрибута в элементе или значение по умолчанию (это значение будет использовано, если атрибут не записан явно в XML документе).
Тип атрибута записывается одним из ключевых слов:
CDATA - строка символов.ID - уникальный идентификатор, однозначно определяющий элемент, в котором встретился этот атрибут; значения такого атрибута не должны повторяться в документе. Они играют ту же роль, что и первичные ключи в таблицах баз данных. IDREF - идентификатор, содержащий одно из значений атрибутов типа id, используется в качестве ссылки на другие элементы. IDREFS - идентификатор, содержащий набор значений атрибутов типа id, перечисленных через пробелы; тоже используется в качестве ссылки сразу на несколько элементов. ENTITY - имя непроверяемой анализатором сущности объявленных в этом же описании DTD. ENTITIES - имена непроверяемых сущностей.NMTOKEN - слово, содержащее только символы, применяемые в именах. Атрибуты этого типа могут содержать имена других элементов или атрибутов, например, для того чтобы ссылаться на них.NMTOKENS - слова, перечисленные через пробелы. NOTATION - обозначение расшифрованное в описании DTD.
Признак обязательности записывается с использование ключевых слов:
#REQUIRED - атрибут надо обязательно записывать в элементе; #IMPLIED - атрибут необязателен, у него нет значения по умолчанию; #FIXED - у атрибута есть только одно значение, которое записывается тут же, через пробел. Пример: <!ATTLIST city type (город | поселок | деревня) "город"> <!ATTLIST pre xml:lang NMTOKEN "ru_RU"> <!ATTLIST pre xml: space (default | preserve) "preserve">
Объявление инструкций по обработке.
Объявление инструкций по обработке начинается с символов <!NOTATION, после них записывается имя инструкции, одно из ключевых слов SYSTEM или PUBLIC (причем слова SYSTEM и PUBLIC здесь равнозначны), затем в кавычках - ее расшифровка.
Пример. <!NOTATION image-gif SYSTEM "viewer.ехе">
Это объявление связывает обозначение image-gif с программой обработки изображений, находящейся в файле viewer.exe.
Объявление элементов.
Каждый элемент документа XML должен быть описан. Объявление элемента начинается с символов <!ELEMENT, после которых через пробел идет имя элемента и его содержимое. Заканчивается объявление символом "больше". По своему содержанию элементы делятся на четыре группы.
Пустой элемент - может иметь атрибуты, но не содержит текст или порожденные элементы. Объявляется следующим образом: после имени элемента указывается ключевое слово EMPTY. Пример: <!ELEMENT element_name EMPTY>
Элемент содержит только порожденные элементы, но не текст. Объявляется следующим образом: после имени элемента в скобках через запятую перечисляются все вложенные элементы. Причем вложенные элементы должны следовать в XML документе в том порядке, в каком они перечислены в объявлении. Пример: <ELEMENT element_name ( elem_1,elem_2)>
Элемент содержит не только порожденные элементы, но и текст. Объявляется следующим образом: после имени элемента в скобках указывается ключевое слово #PCDATA, после которого через запятую, как и в предыдущем случае, перечисляются все вложенные элементы (если они имеются). Пример: <ELEMENT element_name (#PCDATA, elem_1,elem_2)> <ELEMENT element_name (#PCDATA)>
Элемент, открытый для любого содержания. Объявляется следующим образом: после имени элемента указывается ключевое слово ANY. Пример: <ELEMENT element_name ANY>
Иногда из нескольких вложенных элементов или списков (список элементов указанных в скобках) может встретиться только один. В таком случае их имена перечисляются через вертикальную черту( | ). Например:
<!ELEMENT element_name (elem_1,(elem_2|elem_3))> - элемент element_name должен содержать элемент elem_1, а затем либо elem_2, либо elem_3.
Элементы появляются именно в таком порядке.
Если вложенный элемент можно записать в объявляемом элементе несколько раз, то необходимо это указать используя звездочку, плюс или вопросительным знак.
? - элемент или список может встретиться нуль или один раз;
* - элемент или список может встретиться нуль или несколько раз;
+ - элемент или список может встретиться один или несколько раз.
Объявление сущности.
Ссылки на сущности используются как краткие обозначения для громоздких или часто повторяющихся фрагментов документа XML. Сами сущности подставляемые в документ вместо ссылок, объявляются в описании DTD.
Все сущности можно разделить на три группы:
внутренние сущности - задаются при объявлении сущности. Объявление начинается с символов <!ENTITY, после которых через пробел записывается имя сущности и ее значение в кавычках. Например: <!ENTITY lang "XML">
После такого объявления программа-анализатор, увидев в документе ссылку на сущность ⟨, заменить ее на строку XML. Ссылку на сущность можно применять тут же, в описании DTD, уже в следующем объявлении.
внешние сущности - содержатся в отдельных файлах или встроены в программу-анализатор. Для них указывается одно из слов SYSTEM или PUBLIC после которого записывается место их расположения. После ключевого слова SYSTEM указывается URI адрес. После слова PUBLIC идет какое-то общеизвестное объявление, после которого через пробел также указывается URI адрес, которым программа-анализатор воспользуется, если не поймет указанного объявления.параметризованные сущности - используются только внутри описания DTD. Объявление начинается с символов <!ENTITY, после которых через пробел записывается знак процента (%), имя сущности и ее значение в кавычках. Например: <!ENTITY % lang "ru_RU">
Ссылка на параметризованную сущность начинается не с амперсанда, а со знака процента, в примере- %lang;. Введение этой ссылки удобно тем, что при смене языка надо будет поменять значение ru _Ru только в одном месте описания.
Основные декларации разметки
Допустимое в документе XML содержание определяется с помощью четырех типов декларации разметки в DTD. В следующей далее таблице показаны связанные с этими декларациями ключевые слова и их значения:
| ELEMENT | Декларация типа элемента XML |
| ATTLIST | Декларация атрибутов, которые могут быть назначены конкретным типам элементов, а также разрешенных значений этих атрибутов |
| ENTITY | Декларация повторно используемого содержания |
| NOTATION | Декларация форматирования для внешнего содержания, которое не должно быть проанализировано (например, двоичные данные), а также для внешних приложений, обрабатывающих содержание |
Первые два типа связаны с информацией, которую мы рассчитываем найти в документе XML, - элементами и атрибутами.
Последние два типа используются для поддержки. Особенно облегчают жизнь разработчика словаря XML сущности. Как правило, они состоят из содержания, которое настолько часто используется в DTD или документе, что оправдывает создание специальной декларации. Применение этой декларации напоминает оператор include в языках C/C++, когда в качестве замены для содержания используется имя.
Нотации описывают содержание, разработанное не на языке XML. Используются они для того, чтобы объявить конкретный класс данных и связать его с внешней программой. Эта внешняя программа становится обработчиком объявленного класса данных. Например, связав с документом изображение в формате JPEG, разработчик желает, чтобы программа приняла и визуализировала двоичные данные в этом формате. Конечно, в таком случае документ зависит от того, какой обработчик имеется в системе, получающей документ. В интересах портативности и переносимости некоторые авторы не приводят ссылки на обработчики. В таком случае нотация превращается просто в механизм набора текста.
Зачем нужно DTD.
Создавая XML документ разработчик сам решает: как назвать теги, в каком порядке они будут следовать, какие данные будут записаны в том или ином элементе, будут ли у элемента атрибуты или нет и многое другое. Без формального описания структуры документа этим самым документом может воспользоваться только его разработчик. В случае если разработанный XML документ предназначен для передачи во внешний мир, например партнерам по бизнесу, и если к тому же планируется получать в ответ документы, написанные в том же самом формате без определения типов документов (Document Type Definition, DTD) не обойтись. Это связано с тем, что для того, что бы обе стороны могли понимать полученную информацию элементы и атрибуты в документах должны употребляться всеми сторонами одинаково. Определения типа документа вносят строгость и точность в правила написания правильно оформленных документов XML. Хранимые в начале файла XML или внешним образом в виде файла *.DTD, определения типов документов описывают информационную структуру документа. В DTD перечисляются возможные имена элементов, определяются имеющиеся атрибуты для каждого типа элементов и описывается вложенность элементов.
XML используется в качестве средства для описания грамматики других языков. И таким образом разрабатывая некоторый язык для написания XML документов в той или иной области нам придется разработать словарь данной области деятельности. DTD по определению содержат всю информацию которая может появиться в XML документе. Все, что входит в проект, должно быть включено в DTD. Таким образом DTD описания в сущности и является таким словарем. Современный мир меняется достаточно динамично поэтому заранее не известно какая информация может потребоваться в дальнейшем и для того что бы не пришлось часто изменять структуру документов обычно разрабатываемый словарь включает в себя все что может понадобиться для конкретных видов бизнеса или промышленности. Это позволяет использовать определения DTD как средство анализа и проектирования. Приложения XML взаимодействуют друг с другом на основе словарей, которые они понимают, так что определение DTD помогает понять, что может описать приложение.
Другое применение DTD это проверка написанного XML документа на корректность. Правильно оформленные документы, написанные в соответствии со всеми правилами, описанными в спецификации XML, не могут быть проверены на предмет ошибок. Пропущенные ошибки могут вызвать повреждение программы обрабатывающей данные документы, либо ввод в систему неверных данных. Но если документ ссылается на определение DTD, то, используя проверяющей на допустимость анализатор можно проверить, есть ли в нашем документе ошибки. Анализатор затребует DTD и убедиться, что документ соответствует описанным в нем грамматическим правилам. Анализатор обнаруживает структурные ошибки и ошибки содержания, что намного уменьшает объем проверок, выполняемых логикой приложения.
Диаграммы взаимодействия объектов
Диаграммы взаимодействия объектов позволяют проанализировать обмен сообщениями между объектами на более тонком уровне детализации, чем модель потока данных.
Диаграммы взаимодействия объектов неоценимы, если требуется описать взаимодействие между различными системами. Они позволяют определить, какая информация содержится в каком сообщении. Поскольку эти сообщение написаны на языке XML, диаграммы взаимодействия объектов дают нам контекст, требуемый для начала проектирования структуры XML каждого индивидуального сообщения.
Динамическая информационная модель
Динамические модели описывают, что происходит с информацией: примерами таких моделей являются диаграммы рабочих процессов, потоков данных и жизненных циклов объектов. Динамические модели состоят примерно из таких утверждений: "Отделение патологии отправит результаты теста консультанту, отвечающему за пациента". Динамические модели описывают процесс обмена информацией: данные отправляются из одного места в другое с конкретной целью.
Для построения динамической модели можно воспользоваться различными программными системами (например, диаграммы рабочих процессов и диаграммы потоков данных можно построить, воспользовавшись программой BPWin).
Существует несколько подходов к динамическому моделированию:
Модели рабочих процессовМодели потоков данныхОбъектные моделиЖизненные циклы объектовВарианты использованияДиаграммы взаимодействия объектов
Документы и данные
Традиционно документы и данные относились к различным областям. Работа с коммерческими данными была связана с высоко структурированной и формализованной информацией. Публикация документа, напротив, представляет собой организацию процесса создания и выпуска текста, который может быть прочитан людьми.
Таким образом, с одной стороны, основные усилия в мире данных были связаны с автоматизацией, анализом, кодированием и унификацией систем; с другой стороны, в документах главное - обеспечить гибкость, позволяющую авторам информации общаться со своими читателями по возможности творчески.
Сеть Web объединила эти миры. Язык XML стал первым примером технологии, одинаково применимой в обоих случаях.
Традиционный подход, касающийся как обработки данных, так и проектирования документов, предполагает начать с уже имеющейся документации на бумаге. Найдите документы, адекватные стоящей перед вами задаче, определите их структуру с помощью процессов обобщения и абстракции, побеседуйте с пользователями, узнайте, откуда приходит информация в документы, как она передается от одного документа другому и как используется, а затем на основе всего этого составьте модель данных.
В наши дни этот подход бывает, неприемлем, поскольку люди не хотят создавать системы, просто репродуцирующие существующий способ работы. Необходимо знать не только, какая информация должна быть получена, но и почему необходима именно она.
Использование языка XML для хранения постоянной информации
Проекты сообщений определяются в основном динамическими информационными моделями. Но при использовании языка XML для хранения постоянной информации особенно важны статические модели.
При использовании языка XML для хранения постоянной информации встает вопрос о размере одного XML документа. Существуют приложения, в которых имеет смысл поддерживать один документ XML, содержащий гигабайты информации, но это скорее исключения, чем правила. Язык XML не совсем подходит для организации прямого доступа к документу; чтобы обратиться к любой части такого большого документа с помощью современной технологии, его придется анализировать целиком, а это потребует много времени. С другой стороны, противоположная крайность также не является идеальным решением, поскольку наличие большого количества крошечных документов делает невозможным использование богатой структуры XML для представления связей в информационной модели.
Иногда существует естественное отображение одного документа XML на один бизнес-объект (в случае, если последние имеют значительный размер и внутреннюю сложность). Если документы XML используются для постоянного хранения данных, процесс поиска этих данных всегда состоит из двух этапов: сначала надо найти правильный документ, а затем в нем найти интересующие сведения. Для решения этих двух задач используются разные инструменты и методы, поэтому огромное значение имеет определение того, какую информацию поместить в каждый документ.
Основным методом определения правильного размера документа считается концепция "содержимого страницы экрана". Конечно, принимать ключевое решение по проекту на основе того, сколько информации мы хотим передать пользователю за раз, кажется неразумным. Однако на практике это оказывается хорошим тестом. Если сохраняемый документ XML содержит значительно больше информации, чем пользователь когда-либо захочет увидеть на экране, то придется анализировать много данных, на которые он никогда не взглянет; если же для заполнения одного экрана информацией нужно обратиться к сотням сохраняемых документов XML, это вызовет существенную дополнительную нагрузку.
Что делать, если пользователь хочет каждый раз видеть новый небольшой фрагмент информации? Одно из решений: сохранить весь документ DOM в памяти на сервере в области действия приложения. В ответ на запросы пользователей можно фильтровать его и создавать меньшие по размеру документы XML, более точно отвечающие его потребностям. Этот меньший документ можно затем направить клиенту для обработки.
Использование языка XML для сообщений
Использование языка XML для работы с сообщениями системы представляет меньше связанных с проектированием проблем, чем использование его для постоянных данных. Это связано с тем, что каждое сообщение обычно бывает сравнительно автономным, и вопрос о том, что в него включить, естественным образом выпадает из модели обработки.
Разумеется, термин "сообщение" мы используем в широком смысле. Эти сообщения могут быть составлены в стиле электронного обмена данными. Или это могут быть данные, которыми обмениваются подсистемы в форме сообщения XML. Кроме того, сообщение может быть предназначено для отображения на экране. В таком случае, ответ на запрос вернется из базы данных в виде сообщения XML, но клиентская система (или браузер) преобразует его в видимую страницу с помощью соответствующей таблицы стилей.
Существуют некоторые общие принципы проектирования, применимые ко всем сообщениям XML, независимо от их роли:
Проект сообщения должен отражать содержание информации, а не предполагаемое ее использование. Проект должен поддерживать будущие изменения. Составление проекта на языке XML позволяет избежать таких традиционных подводных камней, как фиксированная ширина полей или фиксированный порядок столбцов. Однако проектировщик документа также отвечает за разработку такой структурной информации, которая могла бы предугадать будущие изменения.Для сообщений лучше использовать стандартный тип (если он имеется), а не выдумывать новый. В настоящее время доступно большое количество стандартизированных сообщений, например созданных в рамках инициативы BizTalk. Кодирование данных должно быть настолько близко к принятым кодировкам, насколько это возможно в рамках существующих ограничений производительности. Не стоит создавать идентификаторы, формирующие внутренние зависимости между сообщением и имеющейся базой данных. Сообщения должны быть автономными.
Надо ли включать ненужную в настоящий момент информацию, которая может потребоваться в дальнейшем? На этот вопрос нет универсального ответа.
С одной стороны, легче включить все свойства проекта, а не выбирать те, в которых заинтересован реципиент. Затем можно передать все эти свойства получателю и дать ему возможность проигнорировать ненужные. С другой стороны, глупо посылать лишние данные, учитывая еще проблемы безопасности или секретности. Принимаемое решение должно диктоваться прагматическими соображениями.
Имеет смысл включить в сообщение некоторую официальную информацию, даже если она дублирует доступную из других систем передачи сообщений. Очевидно, это дата и время, личность отправителя и получателя; с помощью серийного номера можно проконтролировать, что сообщение не было утеряно при передаче или отправлено дважды. Для включения всего этого в сообщения XML существуют две причины: реципиенту проще прочитать информацию из сообщения, а не извлекать ее откуда-то еще с помощью специального интерфейса API; и что более важно при архивировании сообщений для последующего аудита, - всю информацию легче сохранять в одном месте.
Этап 1. Именование понятий
Для начала нужно составить список понятий, относящихся к системе. Иногда предлагают даже описать систему на бумаге и выделить все существительные. В любом случае этот этап, как правило, не представляет затруднений.
Далее, и это иногда требует больше времени, надо описать типы объектов. Описание термина должно быть точным, чтобы не возникало разногласий по существу определения. Ценность моделирования в том и заключается, что оно предотвращает появление потенциальных источников непонимания.
По завершении работы, вероятно, получится длинный список типов объектов, и у некоторых будут длинные имена. Следует выбирать такие имена, которые занятые в этом бизнесе люди смогут корректно понять и интерпретировать: дело в том, что они не всегда будут сверяться с написанными определениями.
Помимо именования типов объектов стоит определить также, каким образом можно идентифицировать индивидуальные экземпляры. Возможно, в этом виде бизнеса существует код, который следует знать, или написать его. Надо принимать во внимание, что в схемах кодирования в бизнесе часто обнаруживаются проблемы.
В конце этого этапа мы получим список типов объектов с именами и определениями, по поводу которых достигнуто соглашение.
Этап 2: Таксономия
Таксономия - это термин, используемый в биологии для обозначения системы классификации; в информационном моделировании ее также называют иерархией типов (иногда ее называют еще онтологией). Перечислив и назвав типы объектов, их надо организовать в иерархическую схему классификации. Часто эти иерархические отношения возникают уже на этапе определения типов объектов.
Ключевой здесь является фраза, определяющая принадлежность (в английском языке - is или is kind of). Написав предложение вида "А есть разновидность В" или "Каждое А есть В", вы определили отношения подтипов в вашей таксономии.
Иногда эти действия называются тестом "is а" ("есть", "представляет собой"). Однако будьте внимательны, поскольку эта конструкция используется также и для описания отношений между конкретным экземпляром и его типом, безопаснее писать этот тест в форме "is a kind of" ("представляет собой разновидность").
Идентификация подтипов бывает, полезна при проектировании документа, что более важно, она помогает лучше понять определения типов объектов.
Если вы занимались объектно-ориентированным программированием, то понимаете, как определять иерархии типов. Но программисты часто рассматривают классы объектов, прежде всего в терминах модулей функциональности внутри системы, а не понятий, которые они представляют в окружающем мире. Тогда для обозначения типов объектов используются глаголы, а не существительные - что неверно.
Итак, этап 2 сводится к организации типов объектов в иерархию типов.
Этап 3: Поиск связей
После того как объекты названы, в статическом информационном моделировании надо определить связи, существующие между ними. Связи (на языке UML они называются ассоциациями) можно показать просто сформулировав их в виде обычных предложений или их можно показать графически в виде диаграммы. Для диаграмм, описывающих связи между объектами, существует большое количество нотаций, каждый может выбрать более предпочтительную для себя. Диаграммы следует делать предельно простыми и интуитивно понятными, сосредоточившись на ключевых сообщениях и оставив подробности текстовым документам, которые проще обслуживать.
Существует некая информация, которую надо знать о каждой связи:
Множественность связи показывает сколько объектов каждого типа может принимать в ней участие. Связи типа "один-ко-многим": одна глава содержит много параграфов, один человек покупает много туристических поездок.Связи типа "многие-ко-многим" также часто встречаются: один автор может написать несколько книг, но у книги также может быть несколько авторов.Связи типа "один-к-одному".
При моделировании информации для окончательного представления XML особенно важным типом связей являются связи включения. Множественность этих связей всегда бывает "один-ко-многим" и "один-к-одному". Хотя четкого правила по поводу того, какие объекты образуют связи включения, не существует, можно иногда использовать правила обычного языка: глава содержит параграфы, курорт содержит отели, а отель содержит посетителей. В языке UML определено две формы связей включения. Первая - это агрегации, относительно свободное объединение объектов, позволяющее рассматривать их группу в течение некоторого времени как целое (например, туристическая группа, одни и те же люди могут в разное время входить в разные группы). Вторая форма - композиция. Это более строгая форма; отдельные части целого не могут существовать независимо от него (например, комнаты в отеле не могут существовать независимо от отеля).
Найти подходящие имена для связей иногда бывает нелегко. При записи связей полезно использовать полные фразы типа "отель расположен на курорте" или "человек - это автор книги". Нам не надо использовать эти имена в тегах разметки XML, они присутствуют только в документации на систему.
Итак, в конце этапа 3 мы определили связи существующие между типами объектов в нашей модели.
Этап 4. Описание свойств
Типы объектов и связи формируют скелет статической информационной модели; свойства можно сравнить с плотью на костях. Свойства представляют собой простые значения, ассоциированные с объектами. У человека можно определить рост, вес, национальность и род занятий; отель имеет определенное количество комнат, этажность и ценовую категорию.
Не следует снова включать связи в список свойств объекта: расположение отеля не является его свойством, если мы уже промоделировали его как связь с курортом.
Главное, что нам надо знать о свойствах, - это тип их данных. Определен ли для них фиксированный диапазон значений, являются ли они числовыми, в каких единицах выражаются? Является ли свойство обязательным и есть ли у него значение по умолчанию?
В конце этапа 4 мы завершили формирование статической информационной модели: получили полное описание типов объектов в системе, их связей друг с другом и их свойств.
Модели потоков данных
Модели потоков данных очень напоминают предыдущий тип, но здесь основное внимание уделяется информационным, а не бизнес-систем. Эта модель описывает хранилища данных (data stores), где информация находится постоянно (это может быть база данных в компьютере или просто кабинет с папками), процессоры, манипулирующие с этими данными, и потоки данных, передающие данные от одного процессора другому. Она активно использует статическую информационную модель: последняя описывает, что означают такие концепции, как путешественник или отель, но ничего не сообщает о том, где содержится информация. Напротив, из модели потоков данных становится ясно, что информация о туристической поездке находится в базе данных покупок до завершения поездки и оплаты всех счетов, после чего резюме этой информации передается в маркетинговую информационную систему, а все остальное - в архив.
Модели рабочих процессов
Модели рабочих процессов заостряют внимание на роли людей и организаций в выполнении работы, хранение и обработка информации играют в них вторичную роль. Модель процесса описывает, например, что будет с путешественником, если на отдыхе с ним произойдет несчастный случай. Она определяет, за какие действия отвечает локальный представитель на курорте, агент в стране, где находи курорт и главный офис. В результате становится ясно, кто должен отвечать за организацию медицинской помощи, за перевозку туриста домой и за информирование родственников. Она может описывать различные формы, заполняемые и пересылаемые между участниками, и вообще не привлекать компьютерные системы. Модель процесса обычно фокусирует внимание на ролях, обязанностях и задачах каждого действующего лица системы (actor), а workflow-модель имеет дело с документами, передаваемыми между действующими лицами.
Моделирование данных и XML
Успех любого приложения XML зависит от того, насколько хорошо спроектированы фактически используемые документы XML: они должны быть способны не только нести информацию, которую люди передают друг другу сегодня, но и обладать достаточной гибкостью, чтобы учитывать будущие требования. Для этого необходимо рассмотреть следующие аспекты процесса проектирования:
Моделирование информации (понимание структуры и назначения информации, содержащейся в документах);Проектирование документа (трансляция информационной модели в набор правил или схем для создания фактических документов);Нотации схем (методы записи проекта документа, чтобы он был доступен как для обрабатывающего его программного обеспечения, так и для пользователя-человека).
Моделирование информации
Информационная модель - это описание используемой организацией информации, не зависящее от какой бы то ни было информационной технологии.
Каким образом она структурирована?Что она означает?Кому она принадлежит, и кто отвечает за ее своевременность и качество?Откуда она берется и что происходит с ней в конце?
Моделирование информации имеет такое значение, потому что без модели нет информации, есть только данные. Информационная модель описывает назначение данных.
Любое информационное моделирование преследует две цели, которые не всегда бывает легко сочетать:
Получение абсолютно точных определенийЭффективная коммуникация с пользователями
Существуют два основных типа информационной модели: статическая и динамическая.
В статической модели описываются допустимые состояния системы. В статических моделях описываются типы объектов в системе, их свойства и связи. Описывая объекты, они определяют, разумеется, и их имена. Достичь соглашения по именованию всех объектов означает выиграть половину битвы, именно поэтому информационные модели XML иногда называют словарями.
Динамические модели описывают, что происходит с информацией: примерами таких моделей являются диаграммы рабочих процессов, потоков данных и жизненных циклов объектов. Динамические модели состоят примерно из таких утверждений: "Отделение патологии отправит результаты теста консультанту, отвечающему за пациента". Динамические модели описывают процесс обмена информацией: данные отправляются из одного места в другое с конкретной целью.
Статические модели особенно важны при проектировании базы данных, информация в которой сохраняется в течение долгого времени и используется по самым разным назначениям; в то же время динамические модели лучше подходят для проектирования сообщений, существующих только временно и предназначенных для конкретных целей.
Язык XML, разумеется, может использоваться для представления в системе данных обоих типов - документов и сообщений. Тем не менее, в любом проекте системы необходимо рассмотреть как статические, так и динамические модели, причем оба типа моделей одинаково важны. Лучше начинать работу со статической модели. Отчасти это связано с тем, что именно в ней определяется базовая терминология, а еще с тем, что модели статической информации являются наиболее долговечными аспектами любой информационной системы.
На практике, конечно, граница между долговечной статической информацией и временными сообщениями часто бывает размытой: объекты из статической информационной модели представляют собой события (например, продажа продукта), а документы, которые начинаются как временные сообщения (например, жалобы покупателя), затем архивируются на длительное время. Моделировать такие объекты как статические или как динамические, зависит от личного выбора и обстоятельств.
Объектные модели
Объектные модели содержат как динамический, так и статический компоненты. Динамическая или поведенческая часть определения объекта сосредоточена на том, что может делать или делал каждый объект, представляя для этого набор операций или методов, описывающих его действия.
Представление связей
Для представления некоторых связей модели используются вложенные элементы структуры документа XML. Очевидными кандидатами на подобное представление являются связи "содержания".
Элемент может содержаться непосредственно только в одном порождающем элементе, так что другие связи модели следует устанавливать иначе. На практике это означает использование какой-либо разновидности ссылок.
Представление свойств
Обнаружив свойство в своей информационной модели, мы сталкиваемся с классической дилеммой: в документе XML представлять его с помощью атрибута или вложенного (порожденного) элемента. Приняв решение по этому поводу, можно приступать к остальным задачам.
Рассмотрим практические преимущества и недостатки каждого подхода.
| Атрибуты XML | С помощью определений DTD можно ограничивать принимаемые значения; полезно, если имеется небольшое количество разрешенных значений, таких как "yes" и "nо" | Принимает только простые строковые значения |
| В DTD можно определить значение по умолчанию | Отсутствует поддержка метаданных (или атрибутов у атрибутов) | |
| Использование атрибутов типа ID и IDREF | Неупорядоченность | |
| Небольшие требования к месту на диске (существенно, когда по сети посылаются гигабайты информации) | ||
| Для некоторых типов данных (например, NMTOKENS) возможна нормализация пустых пространств, что избавляет приложение от этих действий | ||
| Легко обрабатывать с помощью интерфейсов DOM и SAX | ||
| Порожденные элементы | Поддержка произвольно сложных и повторяющихся значений | Несколько более высокие требования к дисковому пространству |
| Упорядоченность | Более сложное программирование | |
| Поддержка "атрибутов у атрибутов" | ||
| Возможность расширения при изменении модели данных |
Баланс всех факторов зависит от конкретного приложения.
Представление типов объектов
В общем случае тип объекта в информационной модели будет транслирован в тип элемента в структуре XML.
В качестве имени элемента можно использовать название типа объекта или, если нужно сберечь место на диске, это имя можно сократить. Часто для тегов элементов применяются такие короткие имена. Это связано не с экономией дискового пространства, а с тем, что документ XML становится более читаемым: такие теги не слишком отвлекают внимание от содержания.
Если тип объекта входит в состав иерархии типов, нужно определить, на каком уровне иерархии основать элементы XML.
Проектирование документов XML
Существует два типа данных: информационные хранилища, предназначенные для долговременного хранения данных, и потоки сообщений, передающие временную информацию из одной подсистемы в другую.
Язык XML применим в обоих случаях, но подходы к проектированию различны.
Роль схемы
Формальная роль схем заключается в описании группы всех возможных допустимых документов, или, иначе выражаясь, в описании ограничений, помимо налагаемых самим языком XML, которым должен соответствовать документ, чтобы быть значимым.
Используя слово "допустимость" (validity) в этом контексте, следует быть очень осторожным. В соответствии со стандартом XML допустимость означает соответствие документа правилам, содержащимся в DTD. Но сейчас мы говорим о таких ограничениях, которые не могут быть выражены в DTD, а некоторые из них не могут также быть выражены и в схемах XML.
Схемы как набор ограничений
Одной из задач схем является определение различий между допустимыми и недопустимыми документами. Насколько это, возможно, правила следует выражать таким способом, чтобы программное обеспечение само могло решить, является ли документ допустимым; однако на практике всегда остаются такие правила, которые может интерпретировать только человек.
Конечно, не всегда правильно налагать ограничения. Существует огромное искушение бездумно воспользоваться правом устанавливать правила и сделать систему чрезмерно жесткой. Информационные системы пользуются плохой репутацией из-за их негибкости, и надо вдумчиво использовать ограничения, позволяя людям в процессе работы проявить свой интеллект. В противном случае ограничения могут негативно повлиять на качество информации.
Возможность определять недвусмысленные правила и проверять их программными средствами не означает, что мы должны делать это на каждом удобном этапе обработки. Например, нет необходимости проверять документ в момент его доставки с Web-сервера: прежде всего его допустимость должна быть проверена при поступлении туда. Однако некоторые программисты несмотря ни на что слепо используют во всех случаях проверяющий на допустимость анализатор. Аналогично при отправке документов XML из одной программной системы в другую в рамках той же организации имеет смысл проверять допустимость только на этапе тестирования, но если все работает нормально, одно приложение уже может доверять другому.
Схемы как объяснение
Вторая задача схем заключается в объяснениях - необходимо документировать интерпретацию и использование предоставляемых конструкций так, чтобы отправитель и получатель сообщения одинаково понимали его смысл.
В традициях работы с документами и базами данных роль схем вторична, хотя потенциально она более важна. Частично проблема связана с тем, что схемы как правило не доходят до людей, которым надо знать эту информацию, особенно до пользователей, вводящих данные на экране. В связи с этим большое количество систем страдает от так называемого семантического сдвига, тенденцией сообщества пользователей со временем изменять способ использования системы и значения, связываемого ими с полями данных, даже если программные структуры остаются неизменными.
Поскольку конечные пользователи не будут специально изучать схему, эти схемы должны стать доступными для чтения с помощью приложения: например, следует обеспечить возможность извлекать описание полей данных и показывать его в качестве совета на экранах ввода информации.
<
Статическая информационная модель
При построении статической информационной модели необходимо пройти следующие этапы:
Этап 1. Идентификация понятий, присвоение им имен и их определение
Этап 2. Организация понятий в иерархию классов
Этап 3. Определение связей, множественности и ограничений
Этап 4. Добавление свойств для конкретизации деталей значений, связанных с объектами
Варианты использования
Варианты использования (use cases) анализируют выполнение специфических задач пользователя (например, человек, купивший туристическую поездку, отменяет свой заказ). Вариант использования напоминает модель процесса, но в общем случае заостряет внимание на деятельности одного конкретного пользователя.
Варианты использования могут быть полезны как на этапе моделирования деловой активности, так и при описании внутреннего поведения информационных систем. Одна из опасностей заключается в смешении двух уровней. Лучше этого не делать, поскольку они представляют интерес для различных аудиторий.
Представленный в виде варианта использования диалог пользовательского интерфейса описывает, какой информацией пользователь обмениваются с системой, а не то, как она представлена на экране. Это естественным образом приводит к реализации XML, в которой информационное содержание отделено от особенностей представления.
Выбор подхода к динамическому моделированию
Модели нужны только как рабочие инструменты, дающие возможность при встрече с пользователями прийти к соглашению по вопросу о том, как она должна работать. Поэтому не нужно рассматривать все модели. Достаточно рассмотреть только те, которые действительно дадут необходимую информацию о разрабатываемой проблеме. Эти диаграммы самостоятельно появятся в проекте XML, когда начнется описание сообщения между подсистемами.
Жизненные циклы объекта
Жизненные циклы объекта (на языке UML это называется линиями жизни объекта) также заостряют внимание на индивидуальных объектах, но придерживаются более целостного подхода. Они описывают, что происходит с объектом на протяжении его жизни: как он создается, какие события с ним происходят, как он реагирует на эти события и какие условия приводят в конце к его разрушению.
Жизненные циклы объекта очень полезны для тестирования завершенности модели. Часто наблюдается тенденция к акцентированию внимания только на некоторых событиях за счет остальных. Пока мы не определим, каким образом каждый объект попадает в систему и как он удаляется из нее, полного понимания не будет.