Отказоустойчивость и неоднородная среда
Как отмечалось в разд. 3, в крупных кластерах без совместно используемых ресурсов высока вероятность отказа или замедления отдельных узлов. При выполнении экспериментов, описываемых в этой статье, в среде EC2 мы часто сталкивались и с отказами узлов, и с замедлением их работы (вот примеры уведомлений, которые нам случалось получать: "4:12 PM PDT (Pacific Daylight Time): "Мы изучаем локальную проблему в зоне US-EAST. Из-за этого небольшое число экземпляров в настоящее время недоступно для использования. Мы работаем над восстановлением их работоспособости." или "Сегодня, начиная с 11:30 PM PDT, мы будем производить техническое обслуживание частей сети Amazon EC2. Целью работ является сведение к минимуму вероятности воздействия на экземпляры Amazon EC2, но, возможно, в течение короткого времени, пока соответствующие изменения вступят в силу, некоторым пользователям придется столкнуться с более частой потерей пакетов.").
В параллельных системах баз данных время обработки запросов обычно определяется временем, которое затрачивается на выполнение своей части задачи наиболее медленным узлом. В отличие от этого, в MapReduce любая задача может быть запланирована для выполнения на любом узле при условии, что он свободен, и на него передаются или в нем уже имеются требуемые входные данные. Кроме того, в Hadoop поддерживается избыточное выполнение задач, выполняемых на "отстающих" узлах, чтобы сократить влияние медленных услов на общее время выполнения запроса.
Отказоустойчивость в Hadoop достигается путем перезапуска в других узлах задач, которые выполнялись на отказавших узлах. JobTracker получает периодические контрольные сообщения от компонентов TaskTracker. Если некоторый TaskTracker не общается с JobTracker в течение некотрого предустановленного периода времени (срока жизни (expiry interval), JobTracker считает, что соответствующий узел отказал и переназначает все задачи Map/Reduce этого узла другим узлам TaskTracker. Этот подход отличается от подхода, применяемого в большинстве параллельных систем баз данных, в которых при отказе какого-либо узла обработка незавершенных запросов аварийным образом завершается и начинается заново (с использованием вместо отказавшего узла узла-реплики).
За счет наследования от Hadoop средств планирования и отслеживания заданий HadoopDB обладает аналогичными свойствами отказоустойчивости и эффективной работы при наличии "отстающих" узлов.
Для проверки эффективности HadoopDB в сравнении с Hadoop и Vertica в средах, подверженных отказам и неоднородности, мы выполняли запрос с агрегацией 2000 групп (см. п. 6.2.4) на 10-узловом кластере, и в каждой системе поддерживали по две реплики данных. В Hadoop и HadoopDB срок жизни TaskTracker устанавливался в 60 секунд. В этих экспериментах использовались следующие установки.
Hadoop (Hive): Репликацией данных управляла HDFS. HDFS реплицировала каждый блок данных в некотором другом узле, выбираемом случайным образом с равномерным распределением.
HadoopDB (SMS): Как описывалось в разд. 6, в каждом узле содержится двадцать гигабайтных чанков таблицы UserVisits. Каждый из этих 20 чанков реплицировался в некотором другом узле, выбираемом случайным образом.
Vertica: В Vertica репликация обеспечивается путем хранения дополнительных копий сегментов каждой таблицы. Каждая таблица хэш-разделяется между узлами, и резервная копия каждого сегмента размещается в некотором другом узле, выбираемом по правилу репликации. При сбое узла используется эта резервная копия, пока не будет заново образован утраченный сегмент.
В тестах отказоустойчивости мы прекращали работу некоторого узла после выполения 50% обработки запроса. Для Hadoop и HadoopDB это эквивалентно отказу узла в тот момент, когда было выполнено 50% работы запланированными задачами Map. Для Vertica это эквивалентно тому, что узел отказал после истечения 50% от среднего времени обработки данного запроса.
Для измерения процентного увеличения времени выполнения запроса в неоднородных средах мы замедляли работу некоторого узла путем выполнения фонового задания с большим объемом ввода-вывода. Это задание считывало значения из случайных позиций крупного файла и часто очищало кэши операционной системы. Файл находится на том же диске, на котором сохранялись данные системы.
Не было замечено какой-либо разницы в процентном замедлении HadoopDB с использованием и без использования SMS и Hadoop с использованием и без использования Hive. Поэтому мы указываем результаты для HadoopDB с использованием SMS и Hadoop с использованием Hive и, начиная с этого места, называем эти системы просто HadoopDB и Hadoop соответственно.
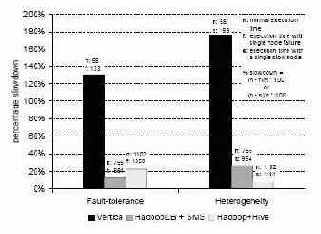
Рис. 11. Эксперименты с отказоустойчивостью и неоднородностью на кластере с 10 узлами
Результаты экспериментов показаны на рис. 11. Отказы узлов замедляли HadoopDB и Hadoop в меньшей степени, чем систему Vertica. В Vertica возрастание общего времени выполнения запроса происходит из накладных расходов на аварийное завершение выполнения запроса и его полное повторное выполнение.
В HadoopDB и Hadoop задачи, выполнявшиеся в отказавшем узле, распределялись между оставшимися узлами, содержащими реплики данных. HadoopDB несколько превосходит Hadoop по производительности. В Hadoop те узлы TaskTracker, которым придется обрабатывать блоки, не локальные для этих узлов, будут вынуждены до начала обработки их скопировать (из реплик). В HadoopDB же обработка проталкивается в реплики баз данных. Поскольку число записей, возвращаемых после обработки запроса, меньше размера исходных данных, HadoopDB не приходится сталкиваться при отказе узла с такими же сетевыми накладными расходами, что возникают у Hadoop.
В среде, в которой один из узлов является исключительно медленным, HadoopDB и Hadoop демонстрируют менее чем 30-процентное увеличение времени выполнения запроса, в то время как у Vertica это время увеличивается на 170%. Vertica ожидает, пока "отстающий" узел завершит обработку. В HadoopDB и Hadoop запускаются избыточные задачи в узлах, которые завершили выполнение своих задач. Поскольку данные разбиваются на чанки (в HadoopDB имеются гигабайтные чанки, а в Hadoop – 256-мегабайтные блоки), разные реплики необработанных блоков, назначенных "отстающему" узлу, параллельно обрабатываются несколькими узлами TaskTracker. Таким образом, задержка из-за потребности обработки этих блоков распределяется между узлами кластера.
В своих экспериментах мы обнаружили, что в планировщике задач Hadoop используется некоторое предположение, противоречащее модели HadoopDB. В Hadoop узлы TaskTracker копируют данные, не являющиеся для них локальными, из отстающих узлов или реплик. Однако HadoopDB не перемещает чанки PostgreSQL в новые узлы. Вместо этого TaskTracker избыточной задачи подключается либо к базе данных "отстающего" узла, либо к ее реплике. Если этот TaskTracker подключится к базе данных "отстающего" узла, то в этом узле потребуется параллельно обрабатывать еще один запрос, что приведет к еще большему замедлению. Поэтому та же особенность, которая приводит к немного лучшим характеристкам HadoopDB, чем у Hadoop, при продолжении работы после сбоя узла, приводит к несколько более высокому процентному замедлению работы HadoopDB при работе в неоднородных средах. Мы планируем поменять реализацию планировщика, чтобы узлы TaskTracker всегда подключались не к базам данных "отстающих" узлов, а к их репликам.